The communication process between Hops and a Hops compliant server is a little more nuanced than simply sending and receiving a single http request and response. The first step in the process occurs when Hops bundles up the referenced Grasshopper definition and sends a http request to an endpoint on the server.
An endpoint is a URL address where the server can be reached to perform a certain function. In this request, the server opens the Grasshopper definition sent from Hops and determines what information will be needed to populate the inputs and outputs for the Hops component. So, the endpoint will be called /io (short for Input Output).
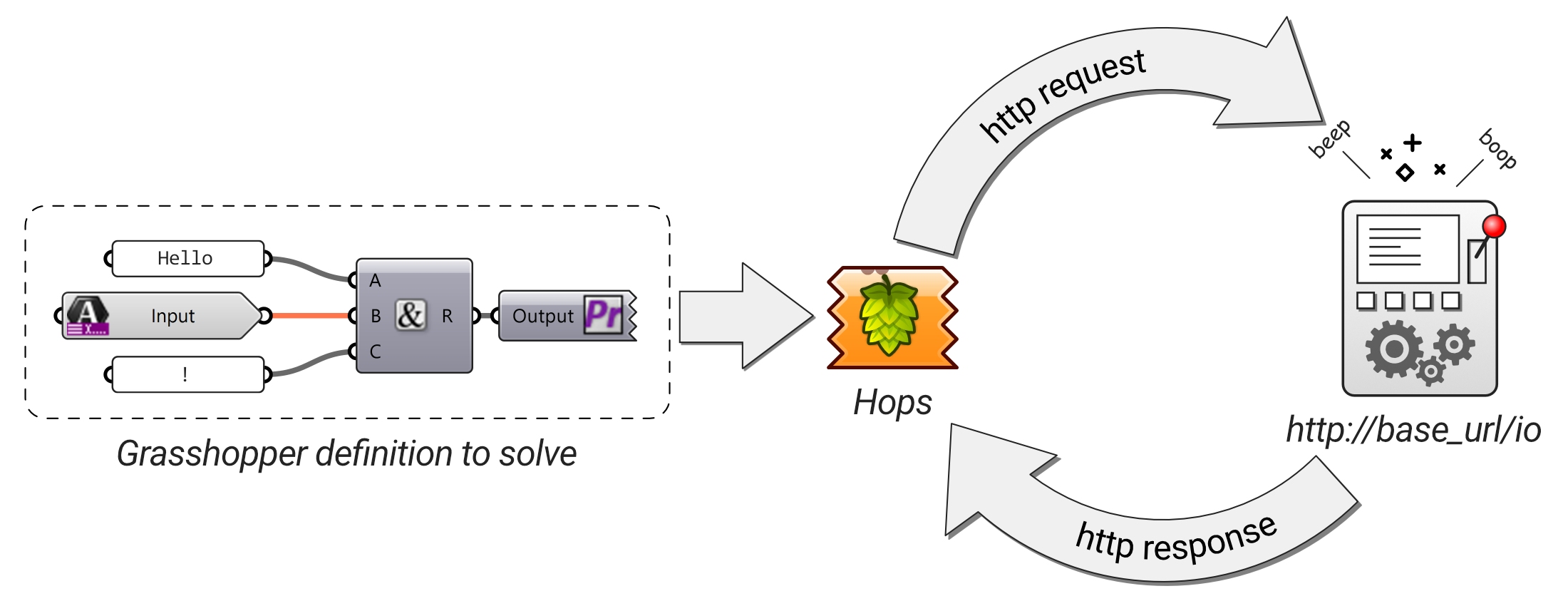
The Hops component should now have enough information to create the necessary inputs and output nodes for itself.

When all of the Hops inputs have been connected to source parameters, it will then send another http request to the server - only this time it will it will send the request to the /solve endpoint. The Grasshopper definition does not need to be resent since it was stored on the server during the /io process. Instead, the data sent in the /solve request only contains a pointer ID which tells the server where to find the correct file and all of the input data.
The http response from the server contains all data which would be returned from running the Grasshopper file in the traditional manner.

To have a better understanding of how each step above works, you can export the last http request and response for both the /io and /solve endpoints directly from the Hops component.