
This chapter is devoted to the advanced data structure in GH, namely the data trees, and different ways to generate and manage them. The aim is to start to appreciate when and how to use tree structures, and best practices to effectively use and manipulate them.
3.1 The Grasshopper data structure
3.1.1 Introduction
In programming, there are many data structures to govern how data is stored and accessed. The most common data structures are variables, arrays, and nested arrays. There are other data structures that are optimised for specific purposes such as data sorting or mining. In Grasshopper, there is only one structure to store data, and that is the data tree. Hold on, what about what we have learned so far: single item and list of items? Well, in GH, those are nothing but simple trees. A single item is a tree with one branch, that has one element, and a list is a tree with one branch that has a number of elements. It is actually pretty elegant to be able to fit all data in one unifying data structure, but at the same time, this requires the user to be aware and vigilant about how their data structure changes between operations, and how that can affect intended results. This chapter attempts to demystify the data tree of Grasshopper.
3.1.2 Processing data trees
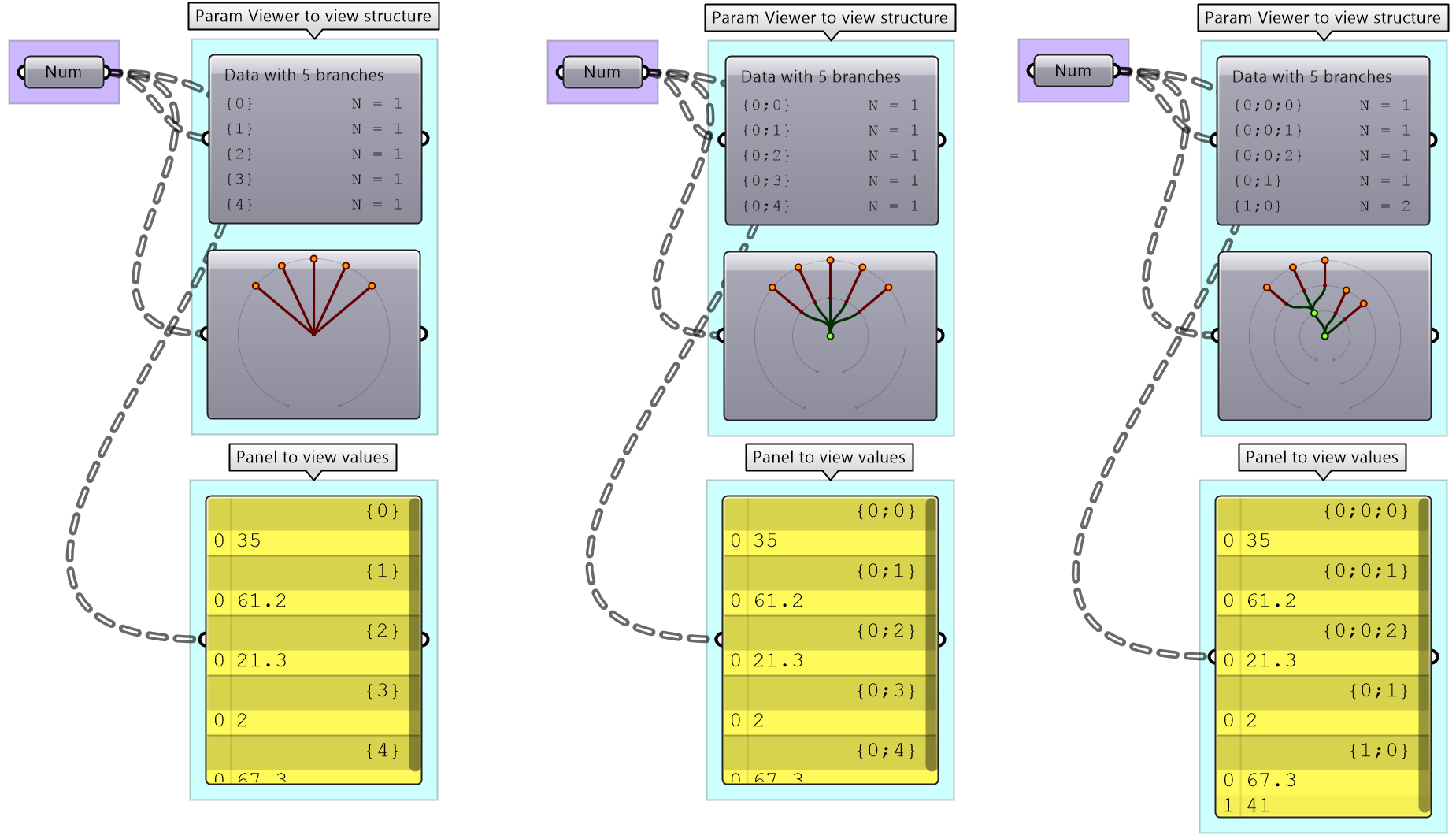
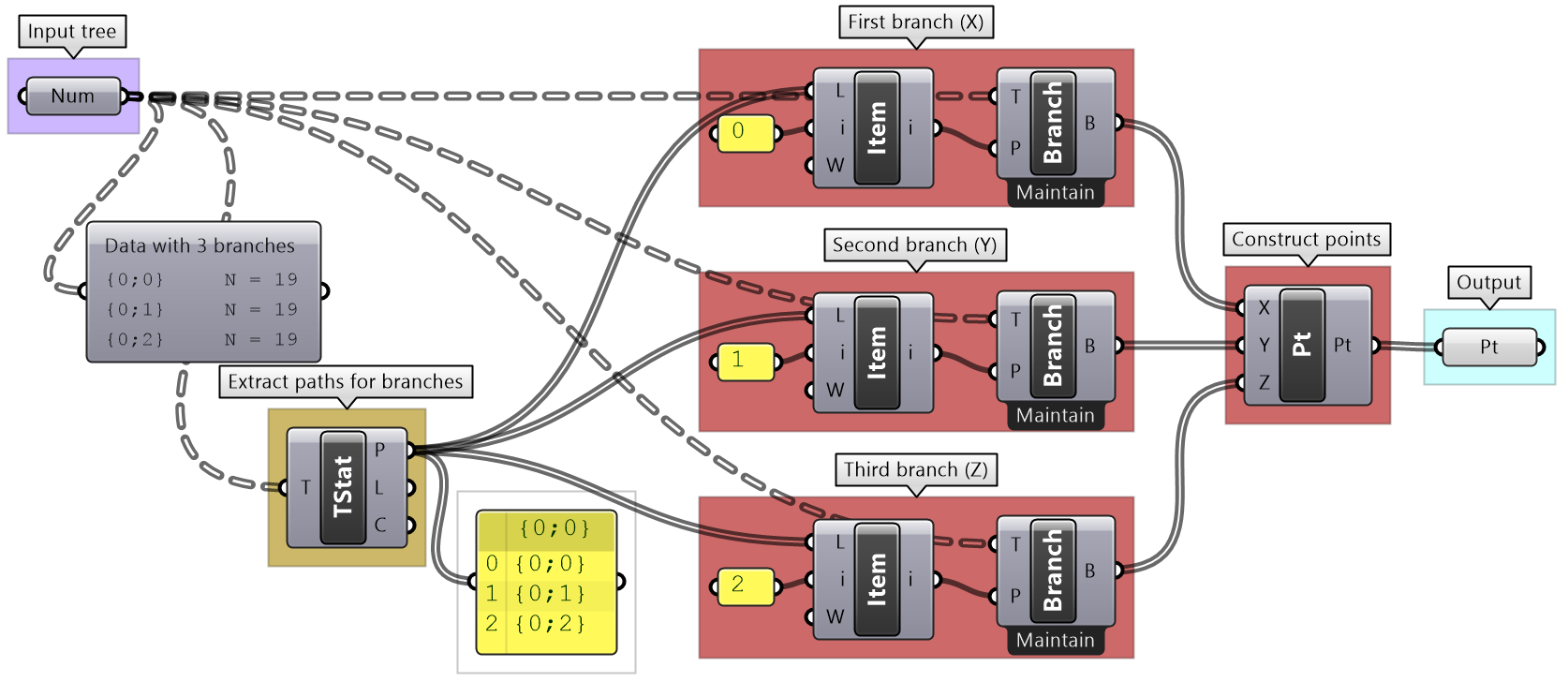
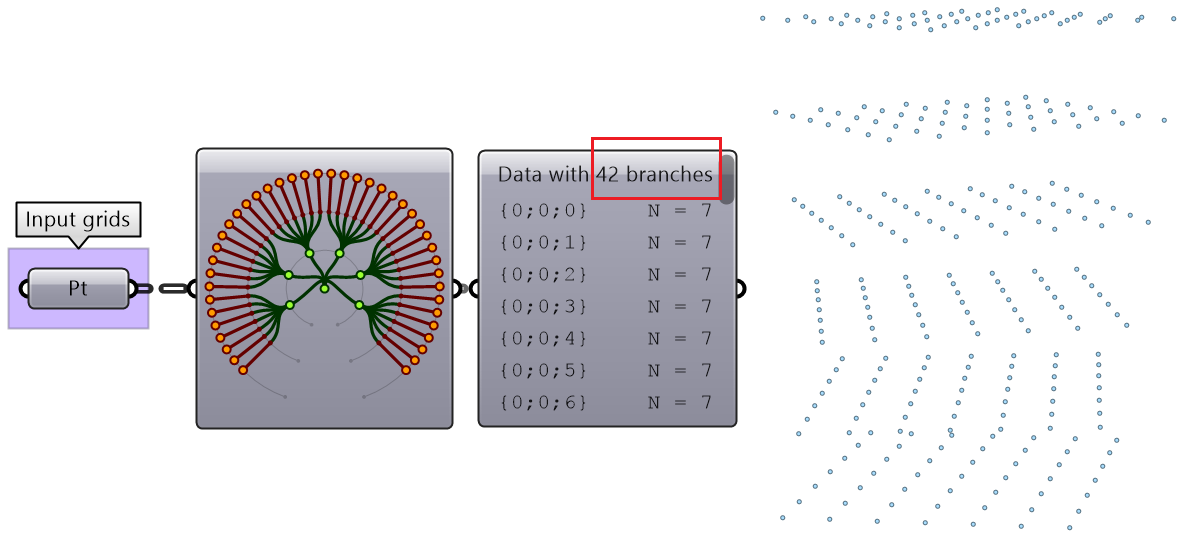
We used the Panel and Parameter Viewer components to view the data structure. We will use both extensively to show how data is stored. Let’s start with a single item input. The Parameter Viewer has two display modes, one with text and one that is graphical. You can see that the single item input is stored in one branch that has only one item.
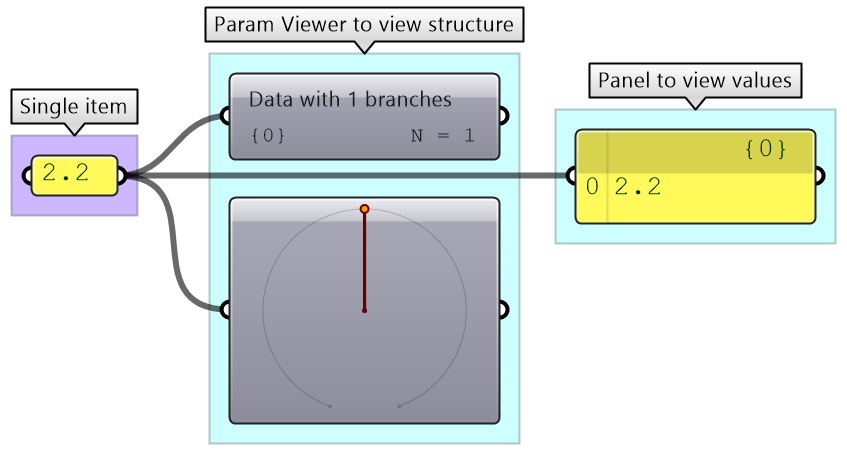
The Parameter Viewer shows each branch address (called “Path”), and the number of elements in that branch as shown in Figure (52).

A list of items is typically stored in a tree with one branch. Figure (53). However, the three items can also be stored in three different branches. Figure (54).
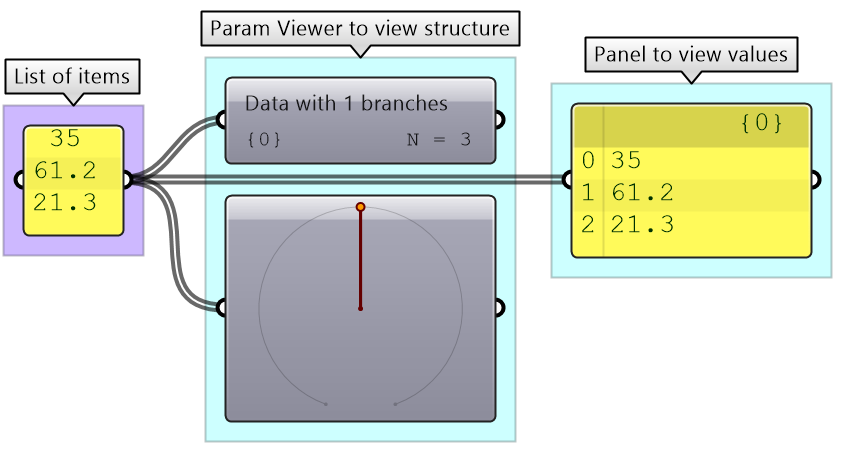
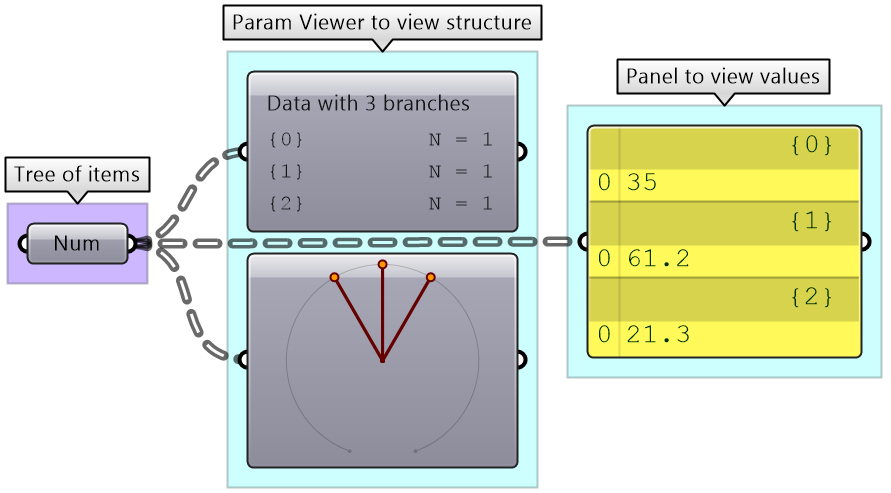
The key to understanding the Grasshopper data structure is to be able to answer the following question:
What is the significance of storing x number of values in one branch vs using x number of branches to store one value in each branch?
The data structure informs GH components about how to match input values. In other words, components may process data differently based on their structure. The following example illustrates how different data structures for the same set of values can affect the result.
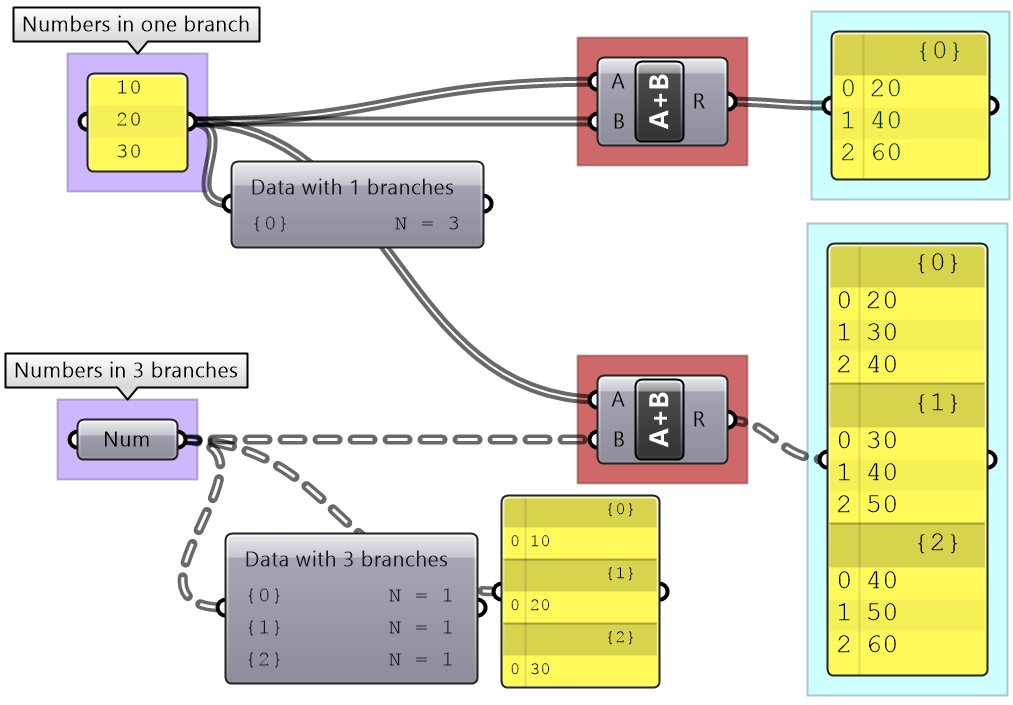
We will elaborate on data tree matching later, but you can already see that GH components do pay attention to the data structure and the result can vary considerably based on it. This is one of the complications inherited in using one unifying data structure in a programming language.
3.1.3 Data tree notation
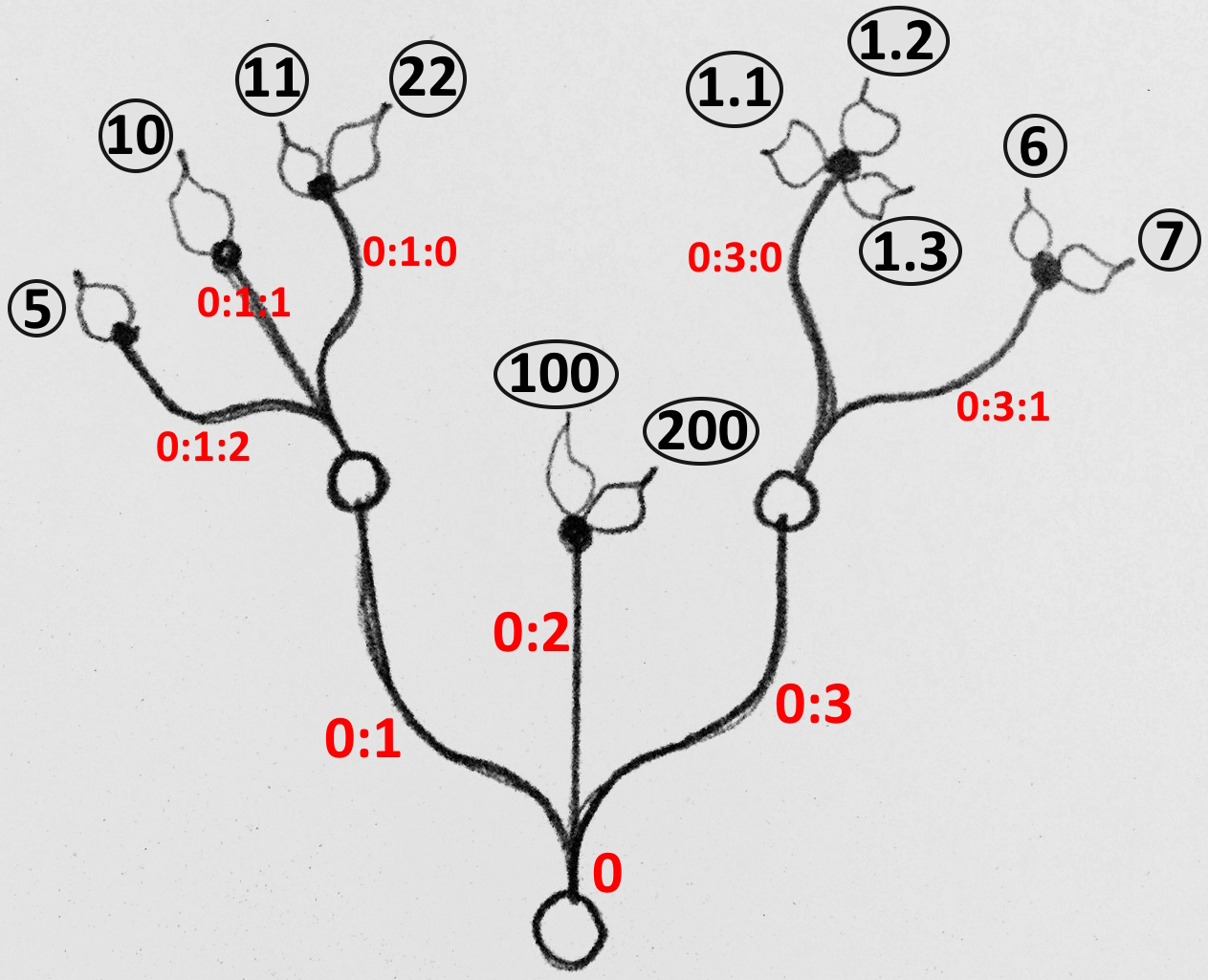
The first step to understanding data trees is to learn the GH notation of trees. As we have seen from the examples, trees consist of branches, and each branch holds a number of elements. The address or path of each branch is represented with integers separated by semicolons and enclosed in curly brackets. The index of each element is enclosed by square brackets. This diagram shows a breakdown of the address of elements in trees.
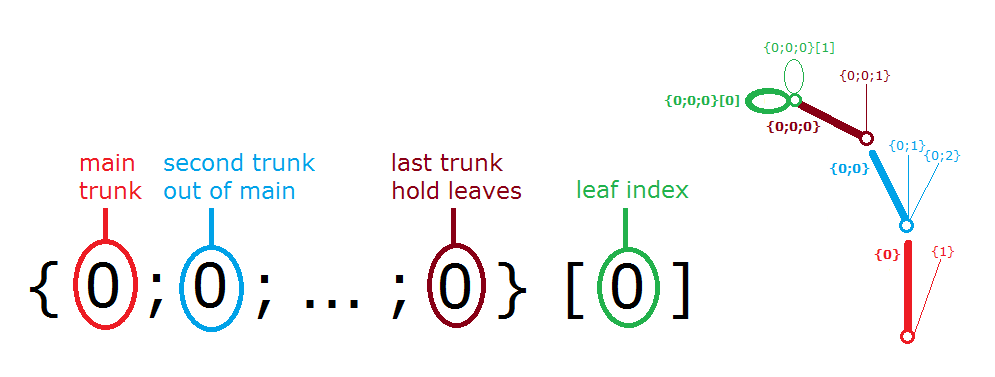
Here are a few examples of various tree structures and how they show in the Parameter Viewer and the Panel.
| Tutorial 3.1.1 Data tree | ||
|---|---|---|
|
||
Solution...
 |
3.2 Generating trees
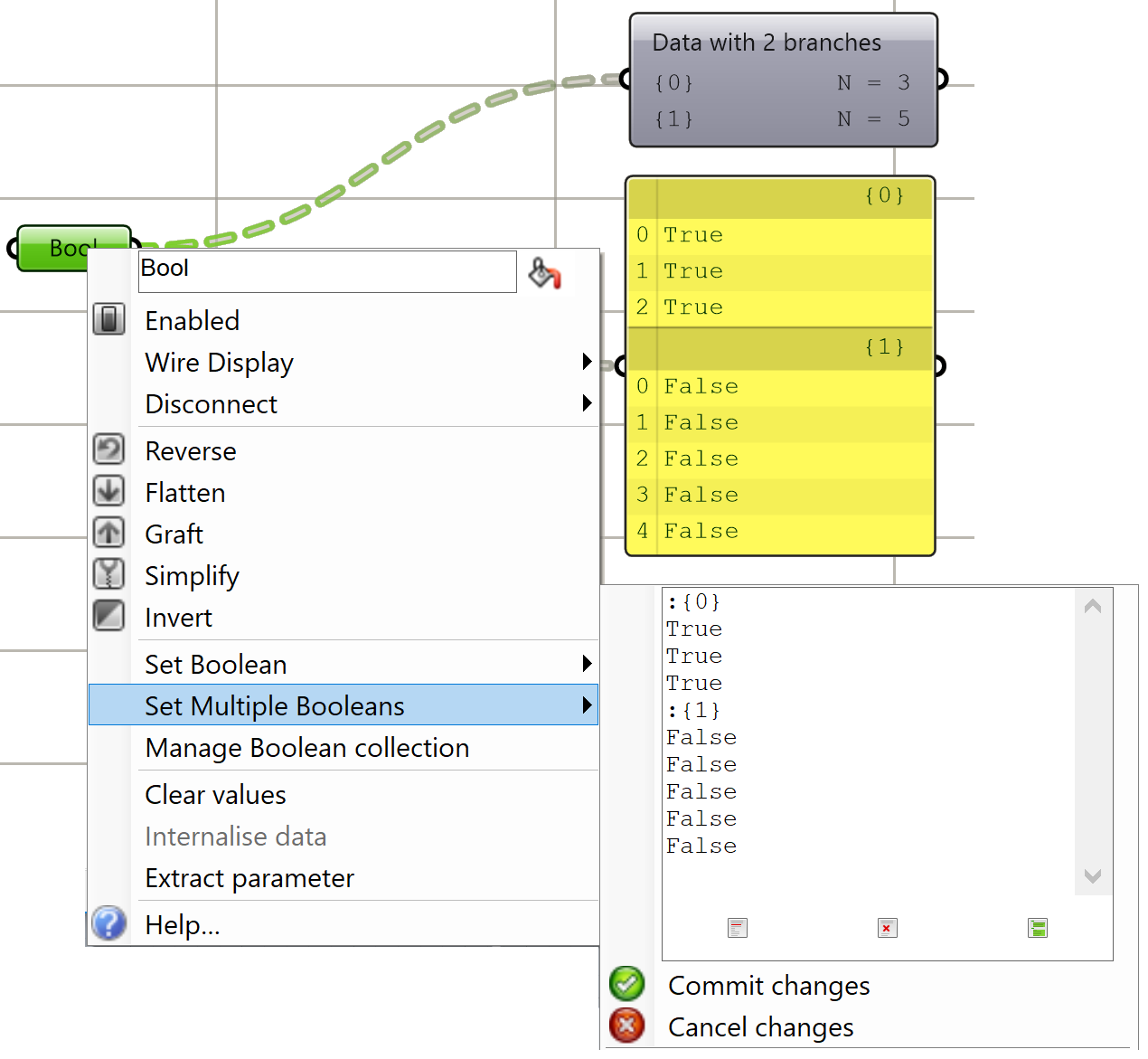
There are many ways to generate complex data trees. Some explicit, but mostly as a result of some processes, and this is why you need to always be aware of the data structures of output before using it as input downstream. It is possible to enter the data and set the data structure directly inside any Grasshopper parameter. Once set, it is relatively hard to change and therefore is best suited for a constant input. The following is an example of how to set a data tree directly inside a parameter.
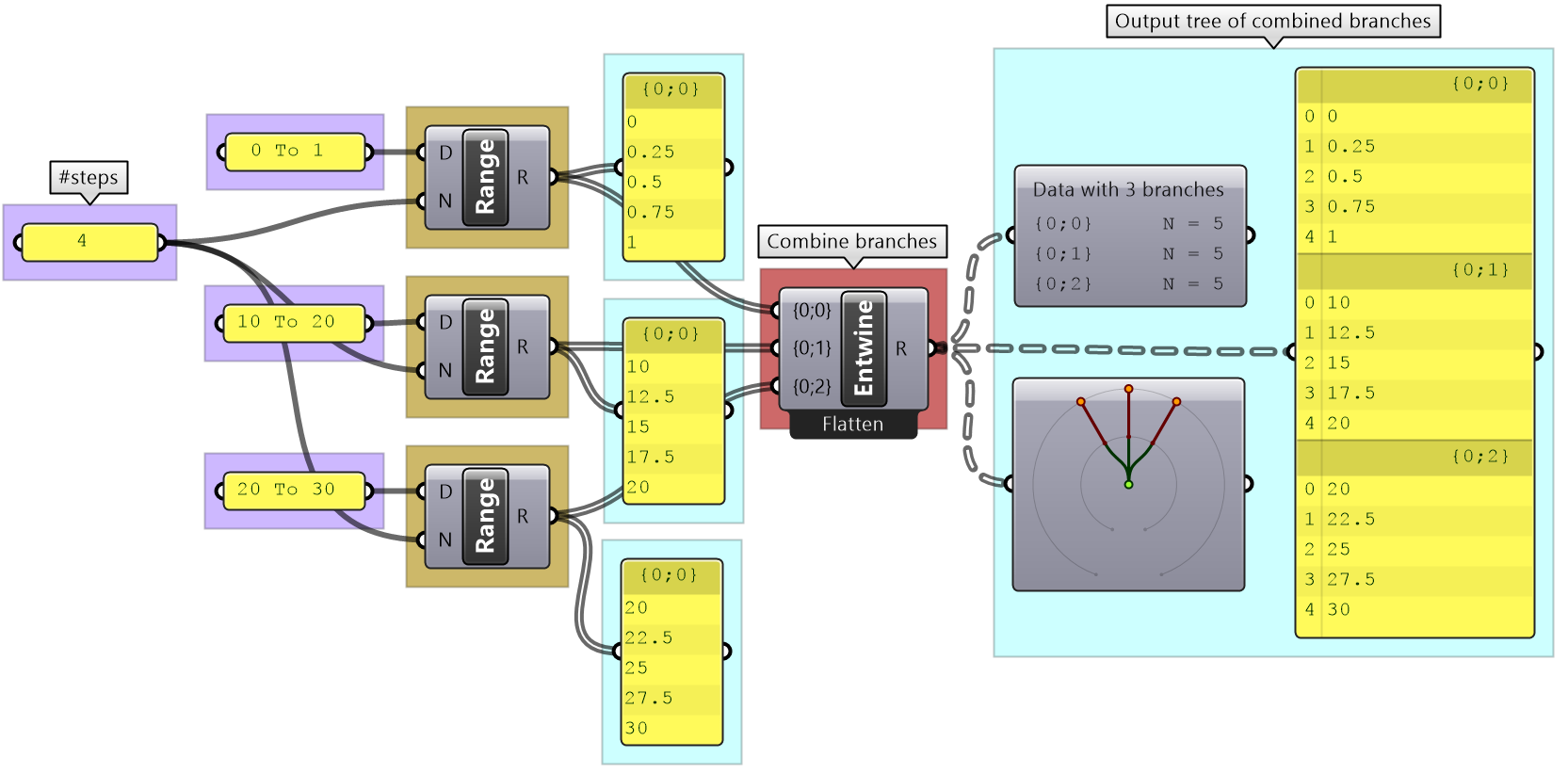
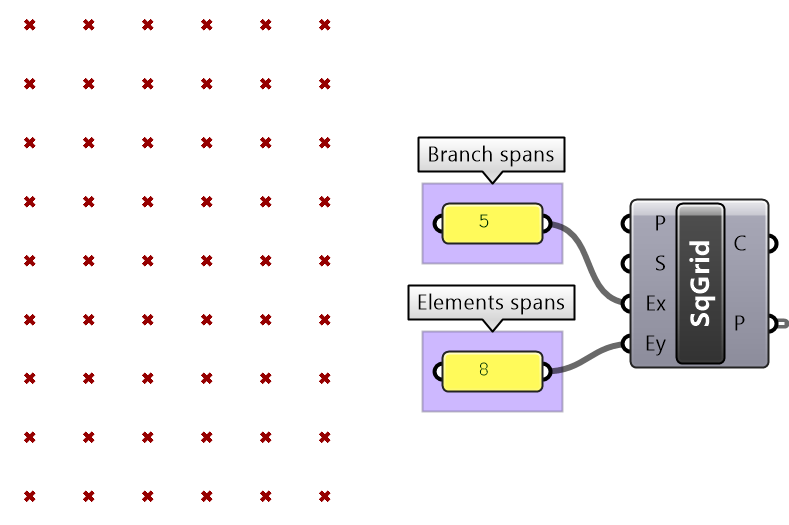
There are many components that generate data trees such as Grid and DivideSrf, and others that combine lists into a tree structure such as Entwine. Also all the components that produce lists can also create a tree if the input is a list. For example, if you input more than one curve into the DivideCrv component, we get a tree of points.
All components that generate lists of numbers (such as Range and Series) can also generate trees when given a list of input.
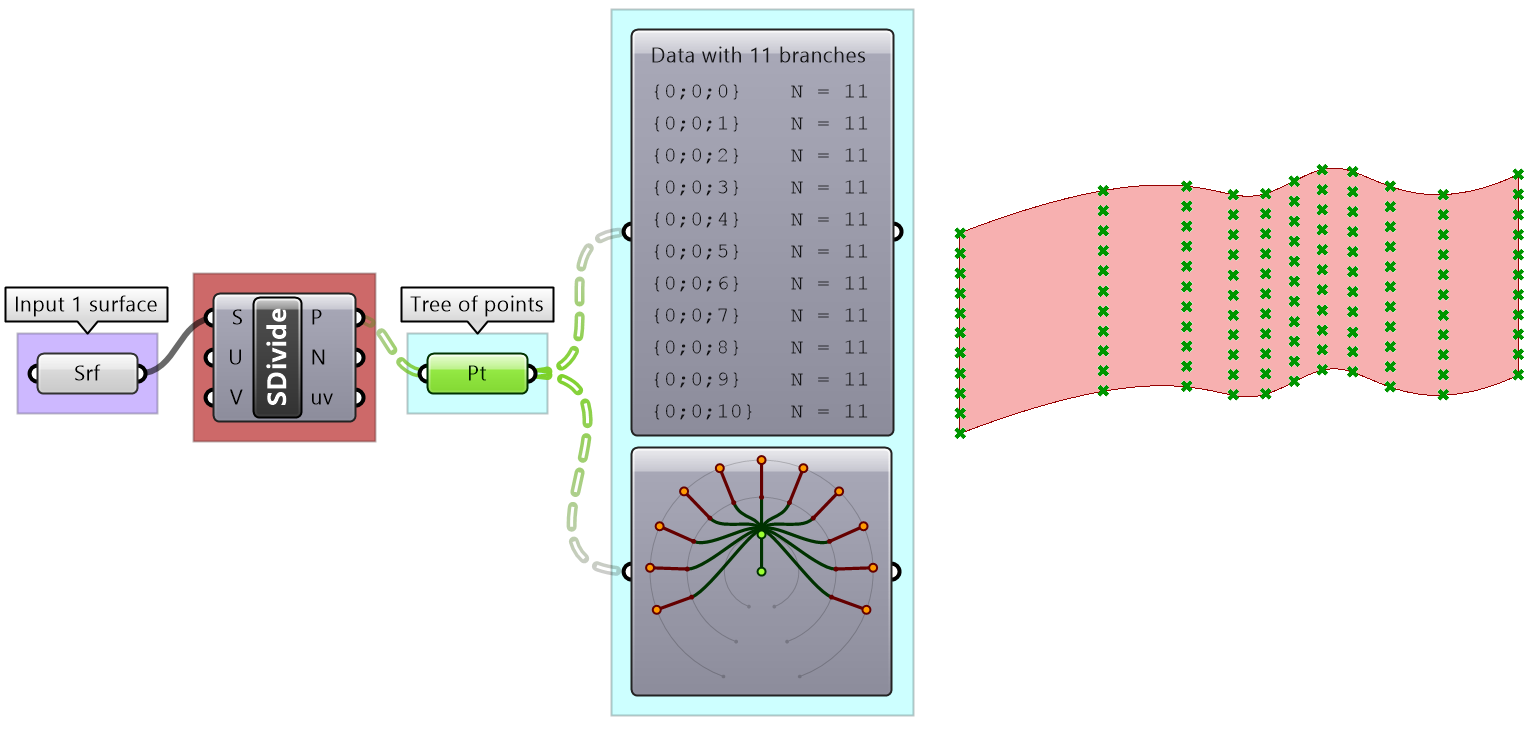
Perhaps one of the most common cases to generate a tree is when dividing a list of curves to generate a grid of points. So the input is one list and the output is a tree.
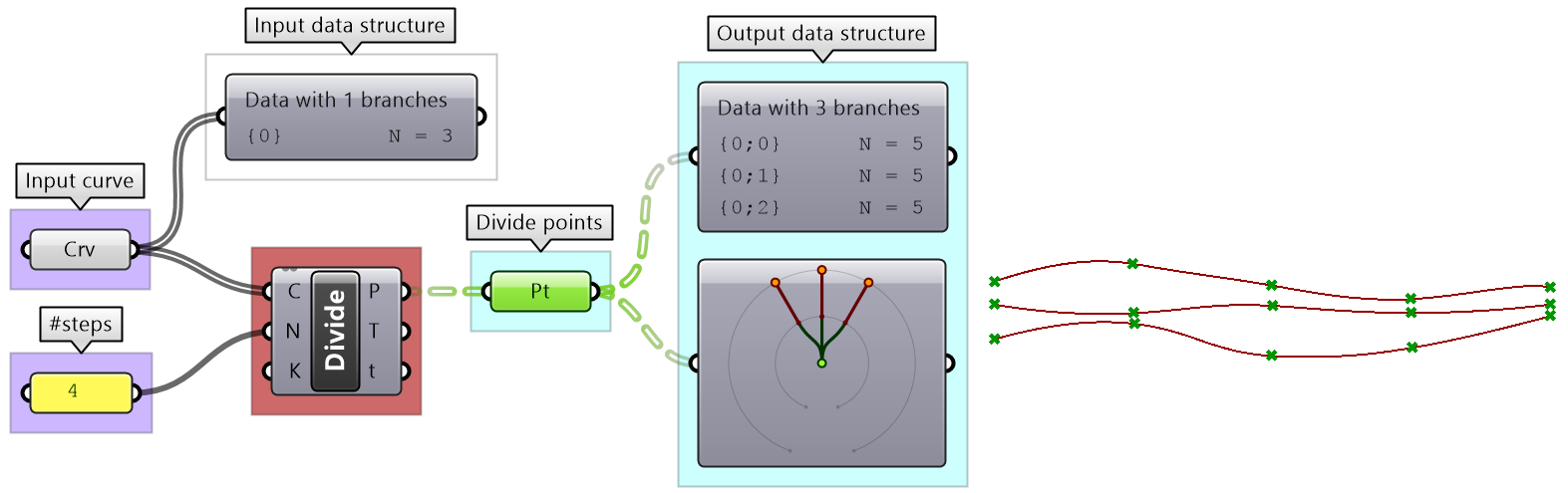
| Tutorial 3-2-1: Generating trees |
|---|
Given the following list of points, construct a number tree with 3 branches, one for each coordinate.
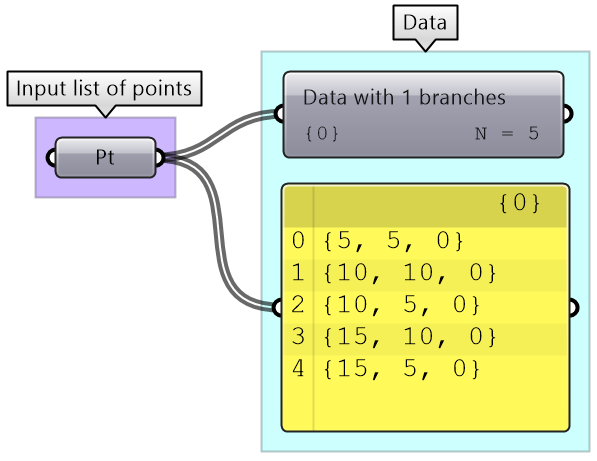
|
Solution...Each input point is a single data item that contains 3 numbers (coordinates). We know we would like to isolate each coordinate into a separate list, then combine them into one data structure. Hence we need to first deconstruct input points (use Deconstruct of pDecon component), then combine the lists into one structure (use Entwine component). 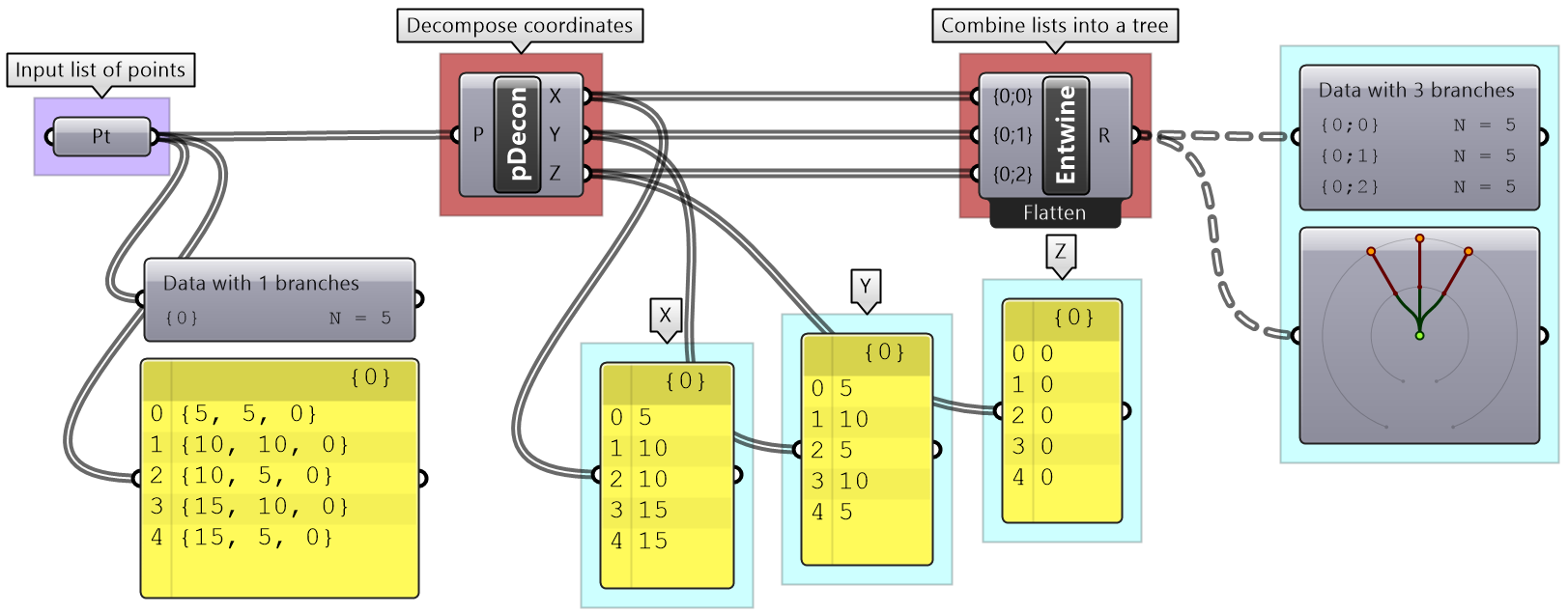
|
3.3 Tree matching
We explained the Long, Short and Cross matching with lists. Trees follow similar conventions to expand the shorter branches by repeating the last element to match. If one tree has fewer branches, the last branch is repeated. The following illustrates common tree matching cases.
3.3.1 Item-to-tree matching
When matching an item to a tree, a matching tree structure is created and the item is repeated. For example when adding a single number to a tree of numbers, the single number is added to every item in the tree and the result is a tree with matching structure to the input tree.
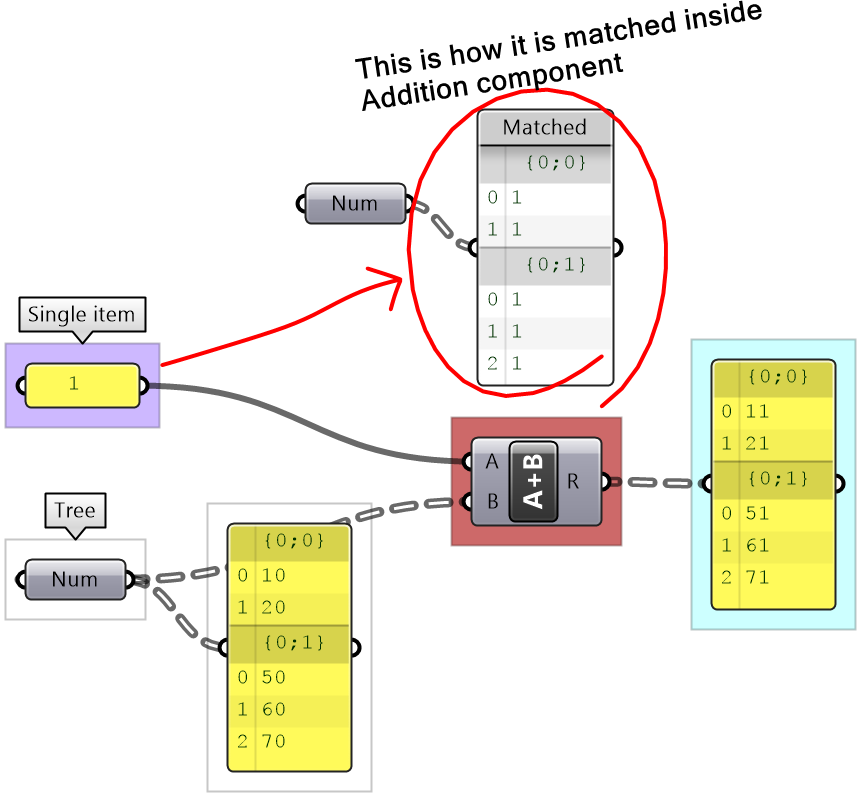
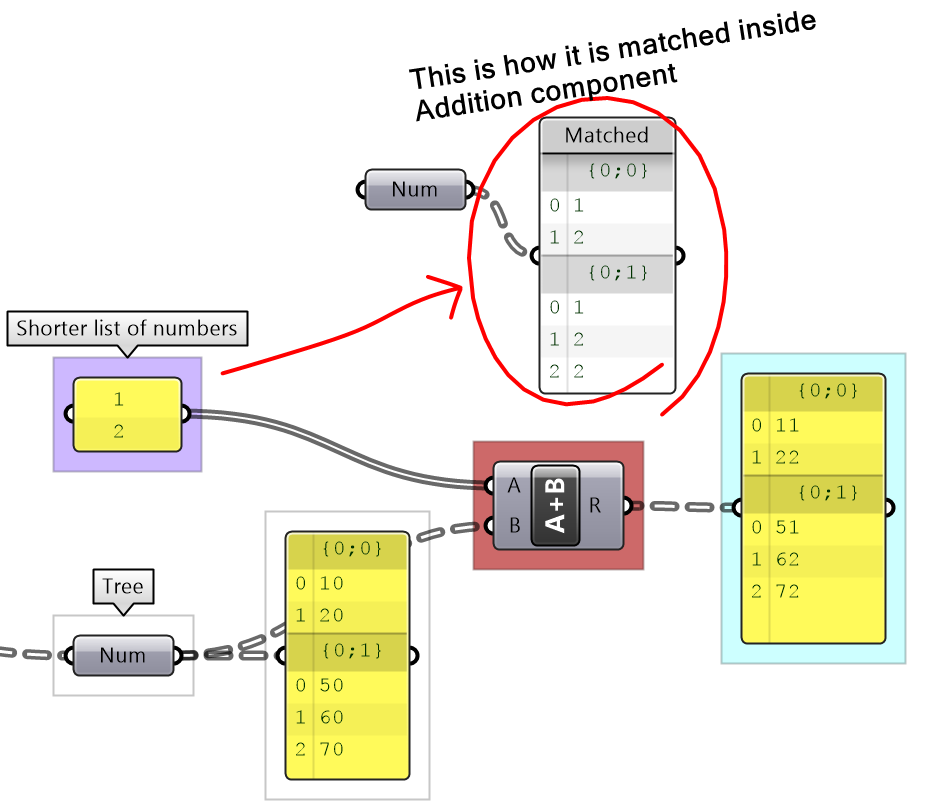
3.3.2 Short-list-to-tree matching
When matching a short list to a tree, where the length of the list is shorter than the tree branches, a matching tree structure is created where the list is repeated in each branch, and the last item in the short list is repeated. See the following example adding a list of two number to a tree of numbers.
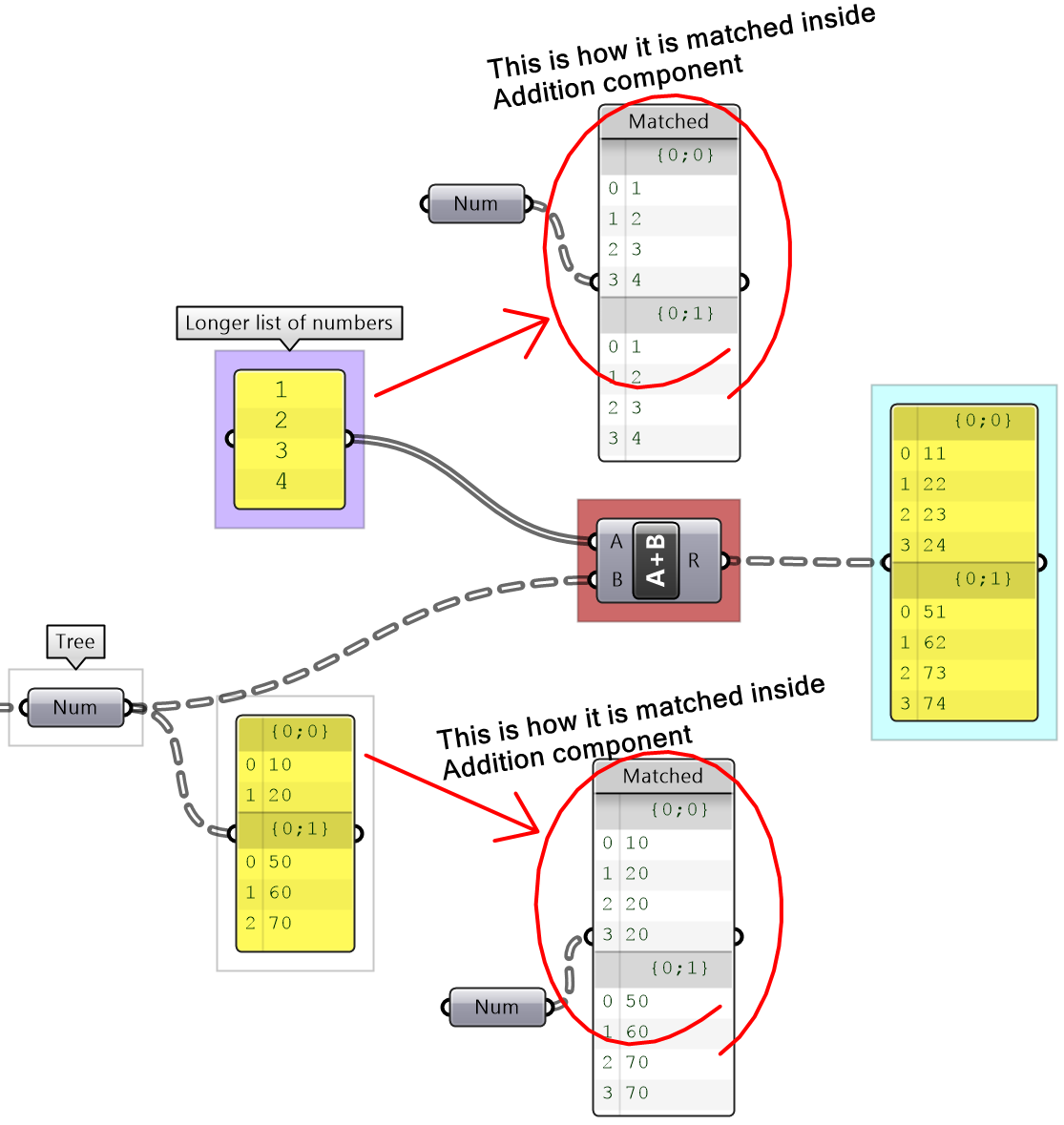
3.3.3 Long-list-to-tree matching
When matching a long list to a tree with branches that are shorter than the list, the tree branches expand to match the length of the list. The last item in each branch is repeated to match the list length Note that the resulting tree structure will be differenent than the input tree. In the following example, both input, the list and the tree, are modified to arrive to a matching structure, then the addition result have than new data structure.
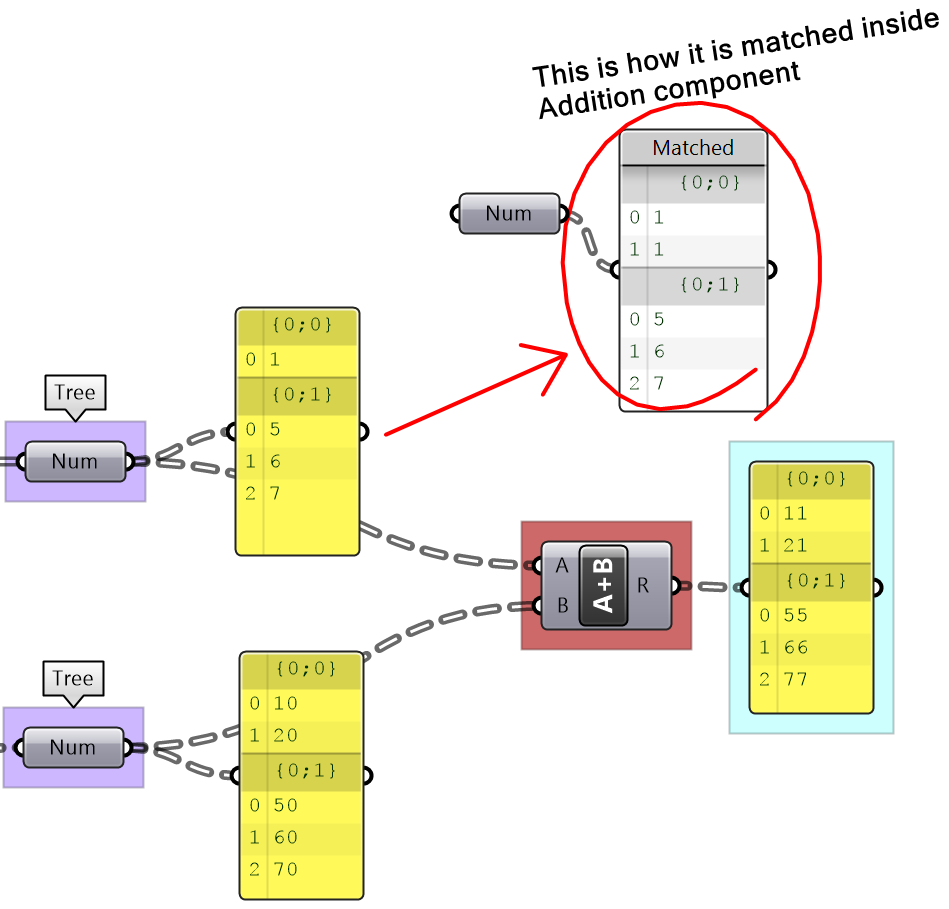
3.3.4 Tree-to-tree matching
There are numerous possibilities when matching two trees, but the basic principle apply. The goal is to find a tree structure that can combine both input tree structure. Let’s assume the case when there is a simple tree with one level of branches that match in depth. There are two possibilities. The first is that both input trees have same number of branches. In this case, the length of the shorter corresponding branches is matched. The output tree might end up matching at least one of the input trees, or be different to both.
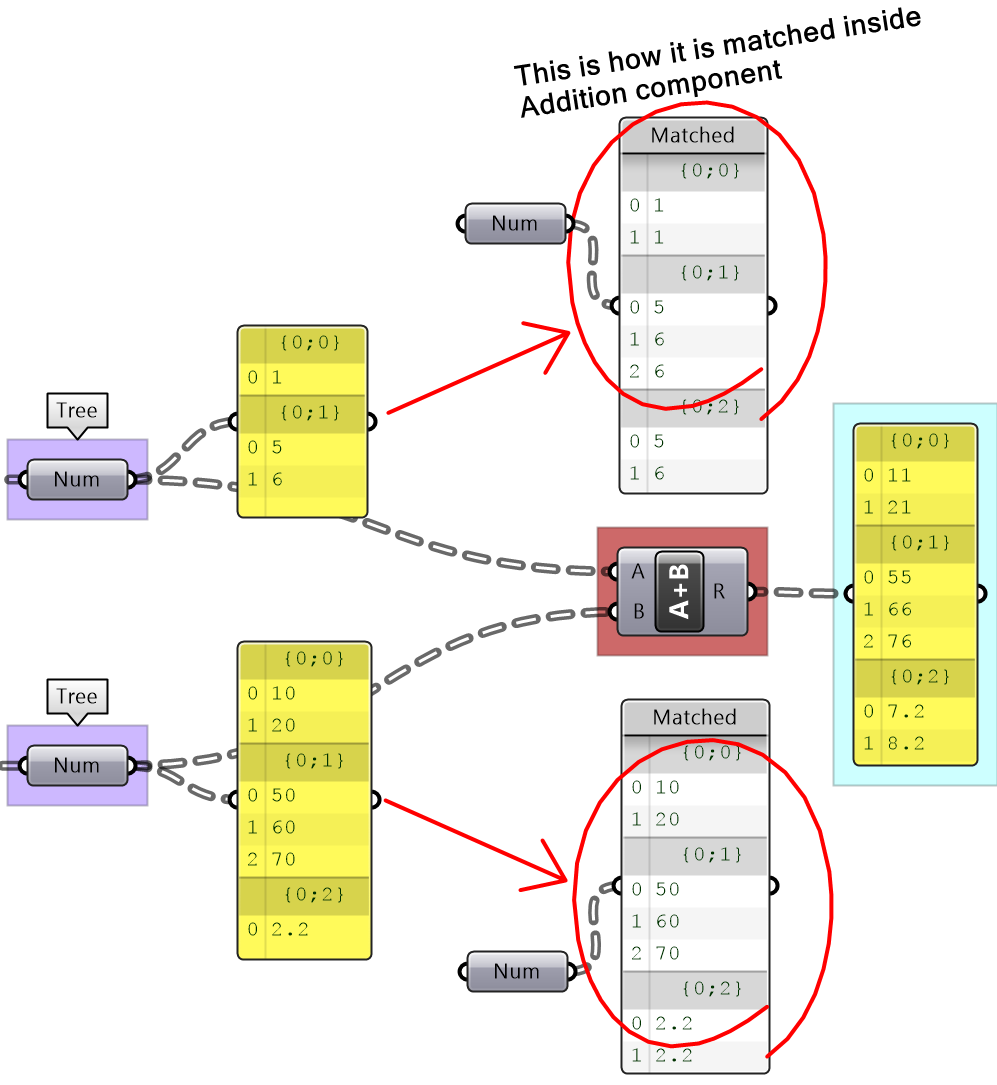
The second possibility is that one tree might have more branches than the other. In that case, new branches are inserted into the smaller tree repeating the last branch, then each branch is expanded (repeating the last item in the branch) to create matching length among all corresponding branches as in the following example.
When working with trees, it is of utmost importance to examine the data structure of each input before using it as input to one component. A small change in the structure can have big impact. For example, the following two trees of numbers appear to be matching at first, but because there is one level depth added to one of the trees (indicating an extra branch near the root of the tree), the result may be different than what is intended.
| Tutorial 3.3.1 Tree matching | |
|---|---|
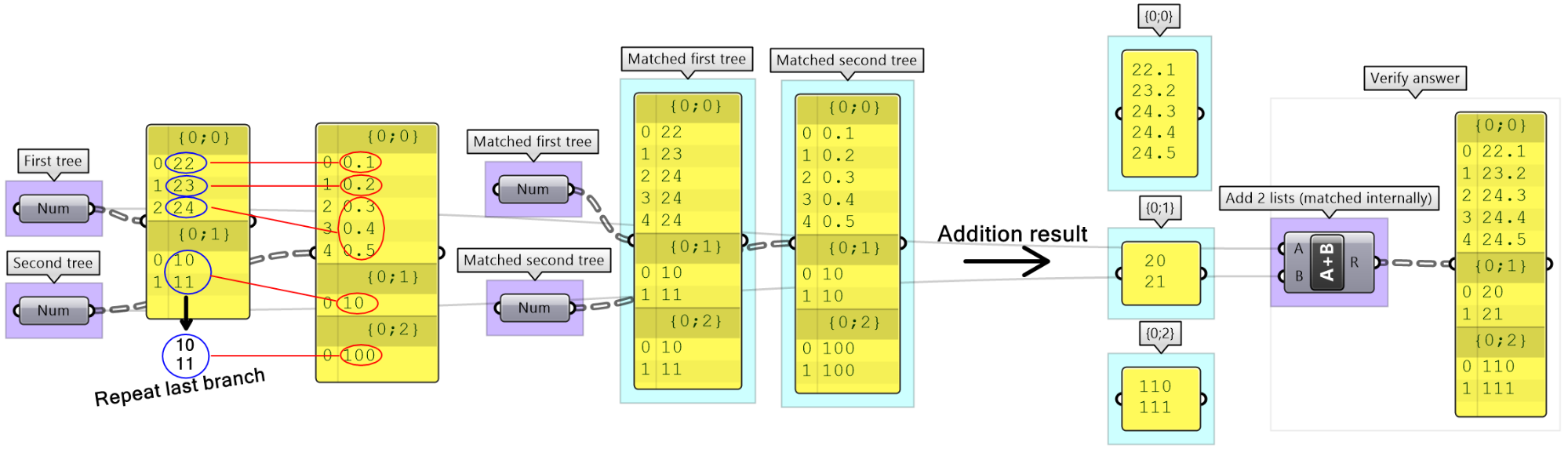
Inspect the following 2 number structures, then predict the structure and result of adding them (with default Grasshopper matching). Verify your answer using the Addition components.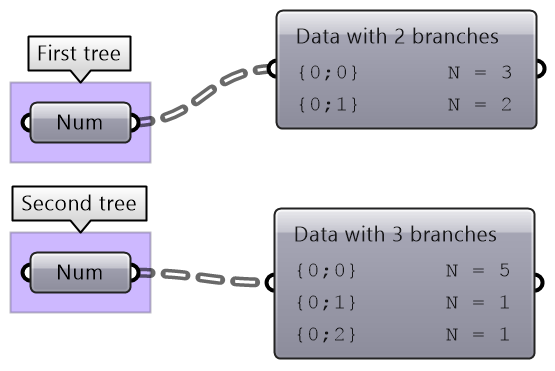
|
|
Solution...
|
3.4 Traversing trees
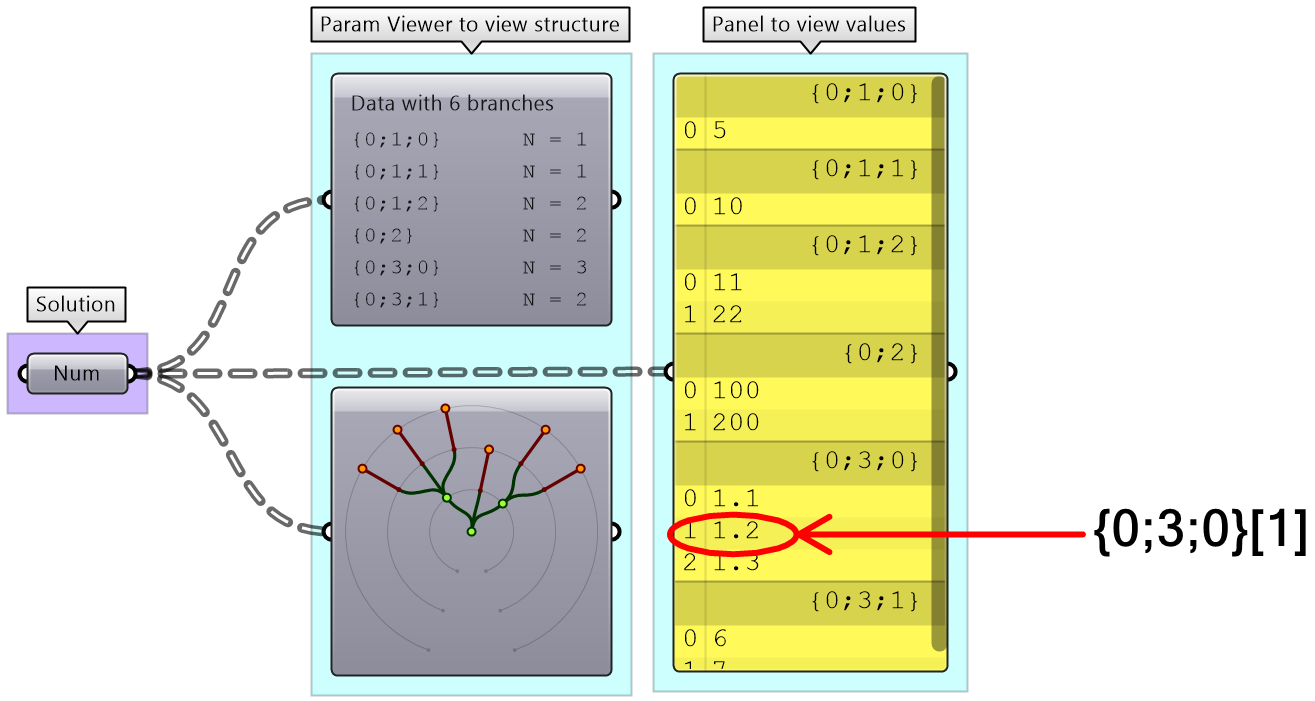
Grasshopper provides components to help extract branches and items from trees. If you have the path to a branch or to an item, then you can use Branch and Item components. You need to check the structure of your input so you can supply the correct path.
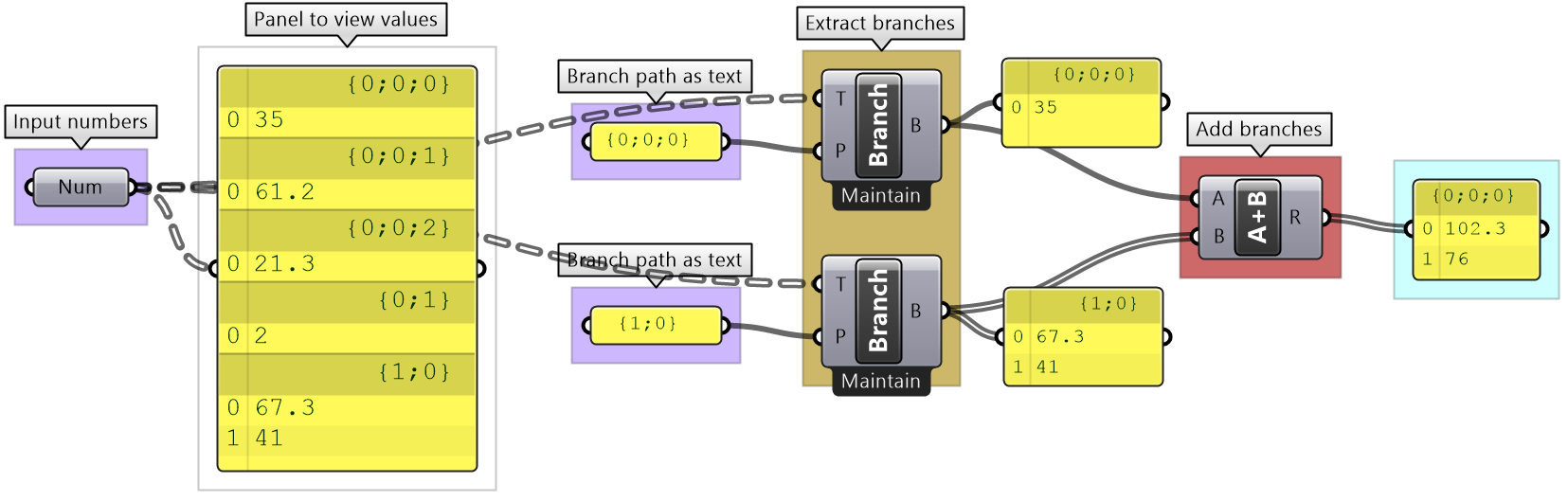
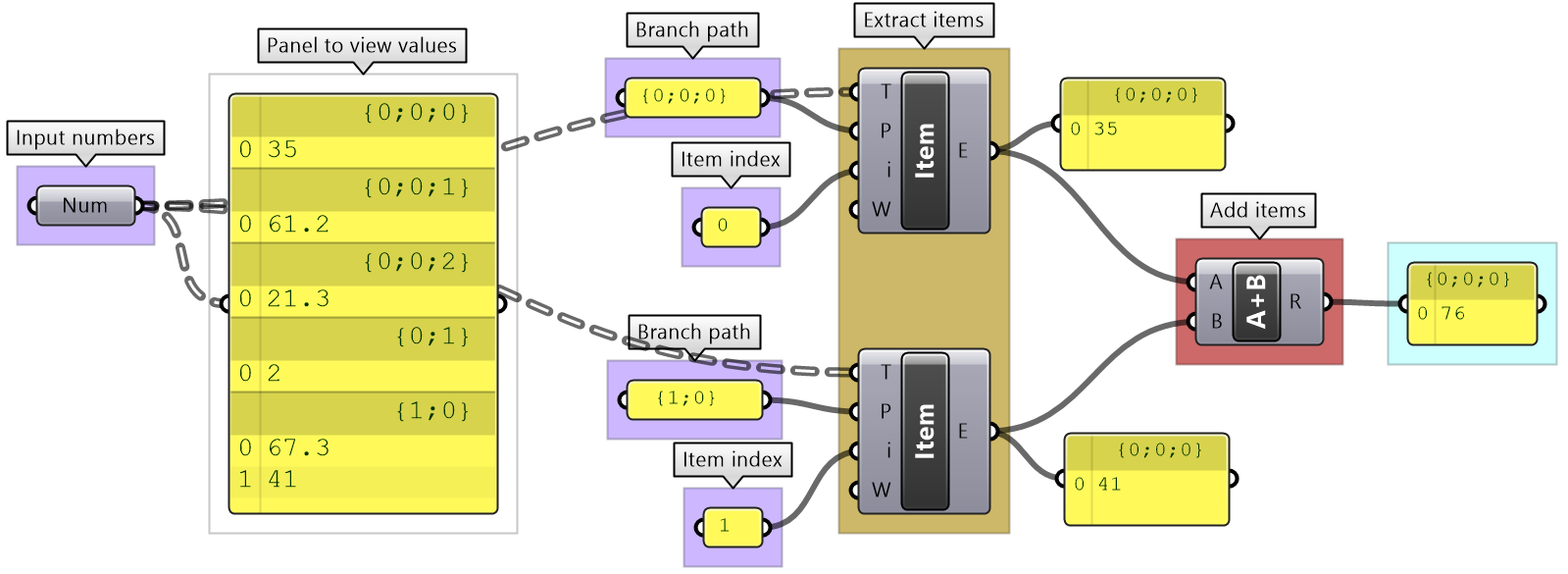
If you know that your structure might change, or you simply do not want to type the path, you can extract the path using the Param Viewer and List Item components.
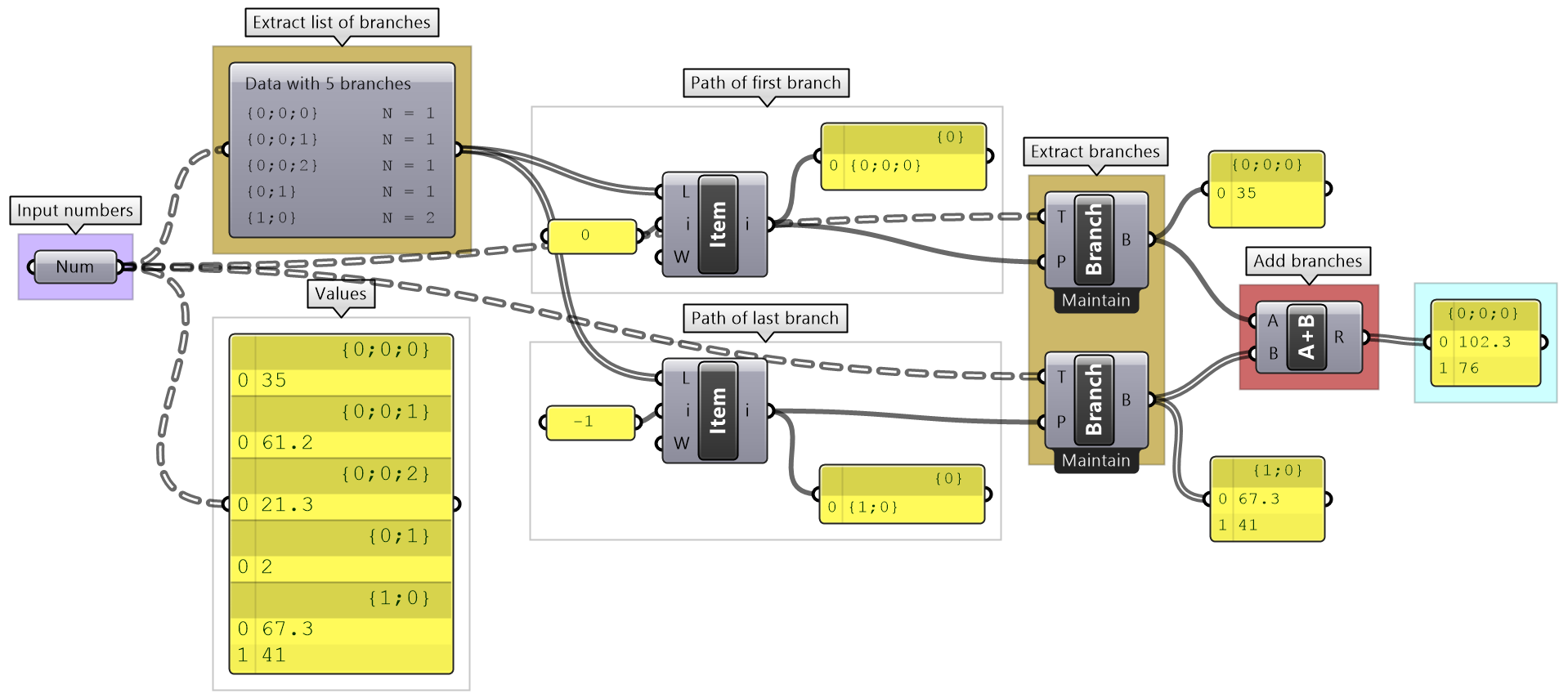
| Tutorial 3.4.1 Traversing trees | |
|---|---|
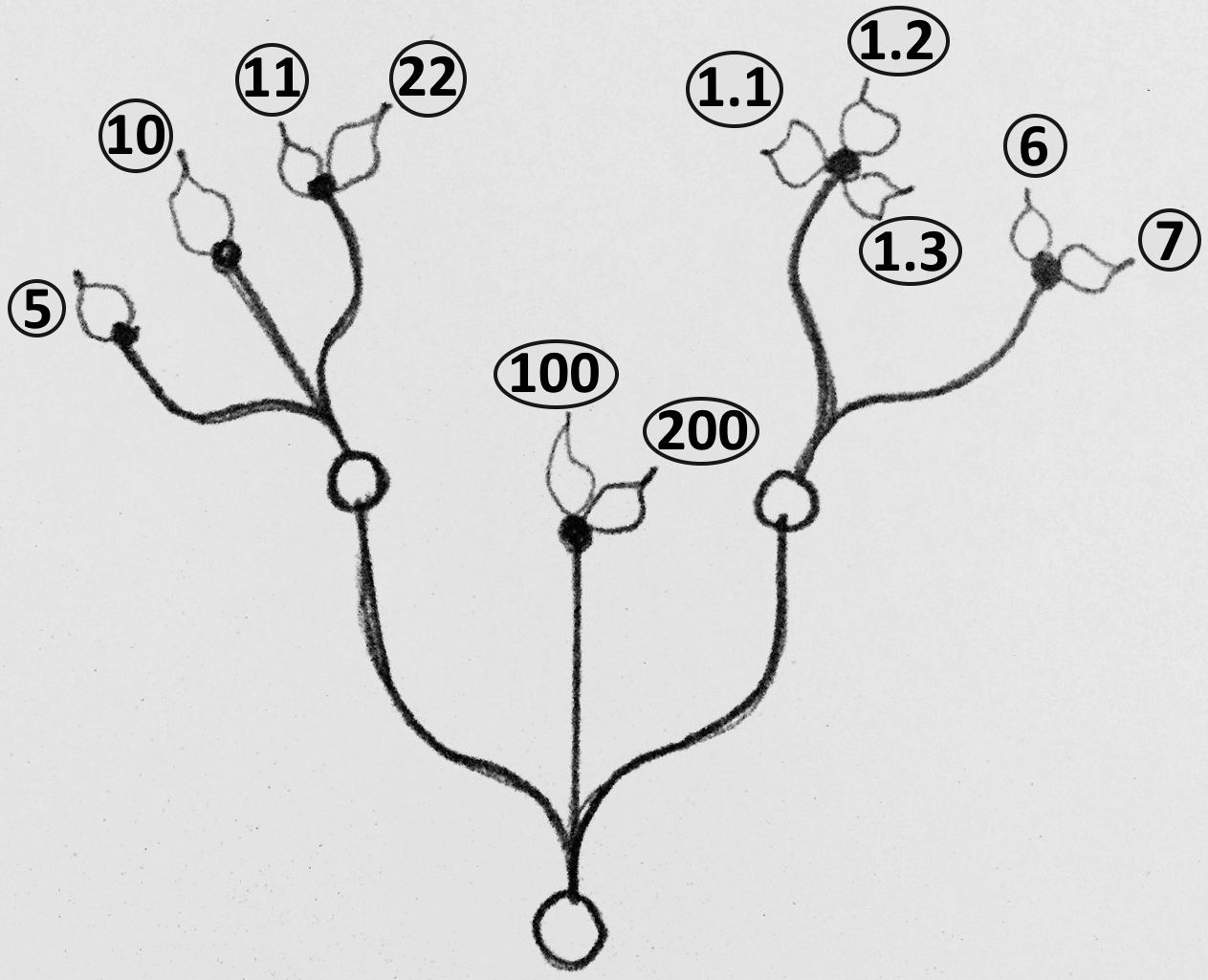
The following tree has 3 branches for each one of the coordinates (x, y, z) of some list of points. Use that tree to construct a list of these points.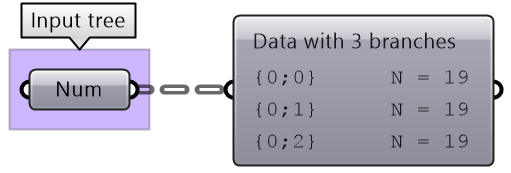
|
|
Solution...
|
3.5 Basic tree operations
Basic tree operations are widely used and you will likely need them in most solutions. It is very important to understand what these operations do, and how they affect the output.
3.5.1: Viewing the tree structure
As we have seen in the data matching, different data structures of the same set of elements produce different results. Grasshopper offers three ways to view the data structure, the Parameter Viewer in text or diagram format, and the Panel.
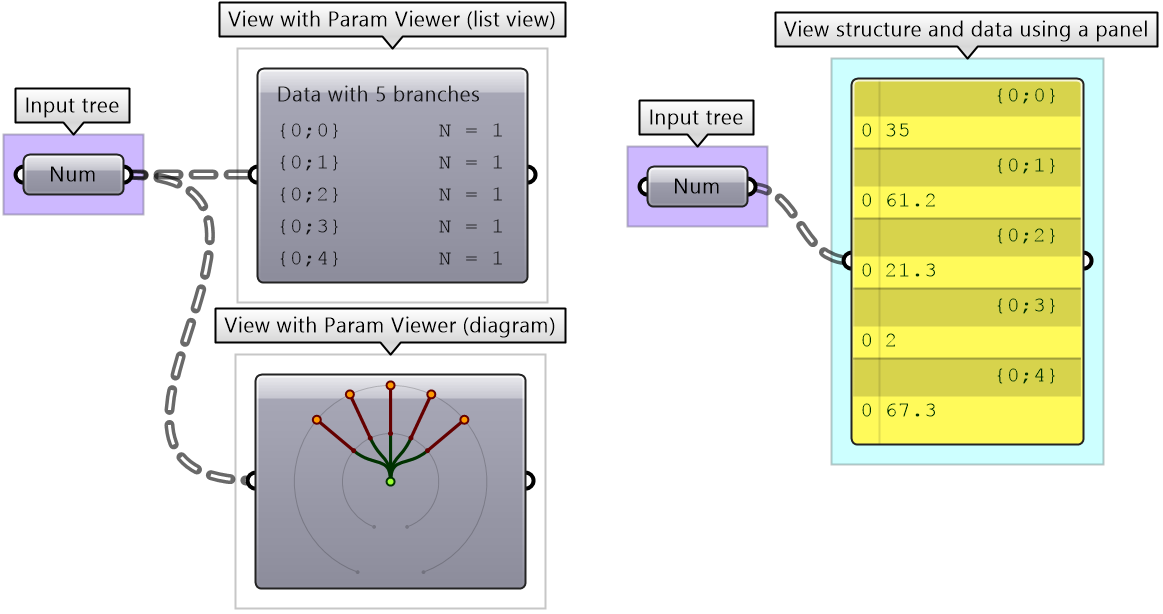
Tree information can be extracted using the TStats component. You can extract the list of paths to all branches, number of elements in each branch and the number of branches.
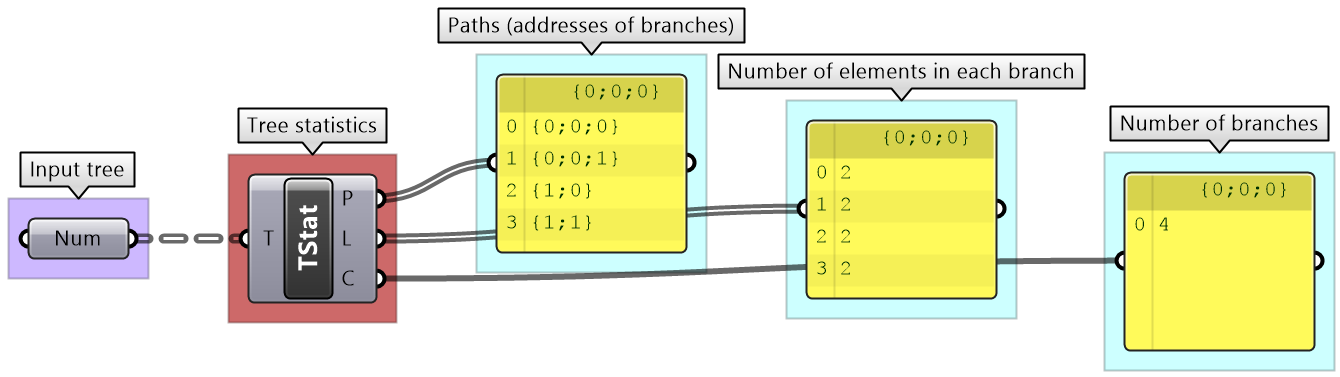
3.5.2 List operations on trees
Trees can be thought of as a list of branches. When using list operations on trees, each branch is treated as a separate list and the operation is applied to each branch independently. It is tricky to predict the resulting data structure and therefore it is always important to check your input and output structures before and after applying any operation. To illustrate how list operations work in trees, we will use a simple tree, a grid of points, and apply different list operations on it. We will then examine the output and its data structure.
| Common list operation and how they apply to trees |
|---|
List Item: Select items at specific index in each branch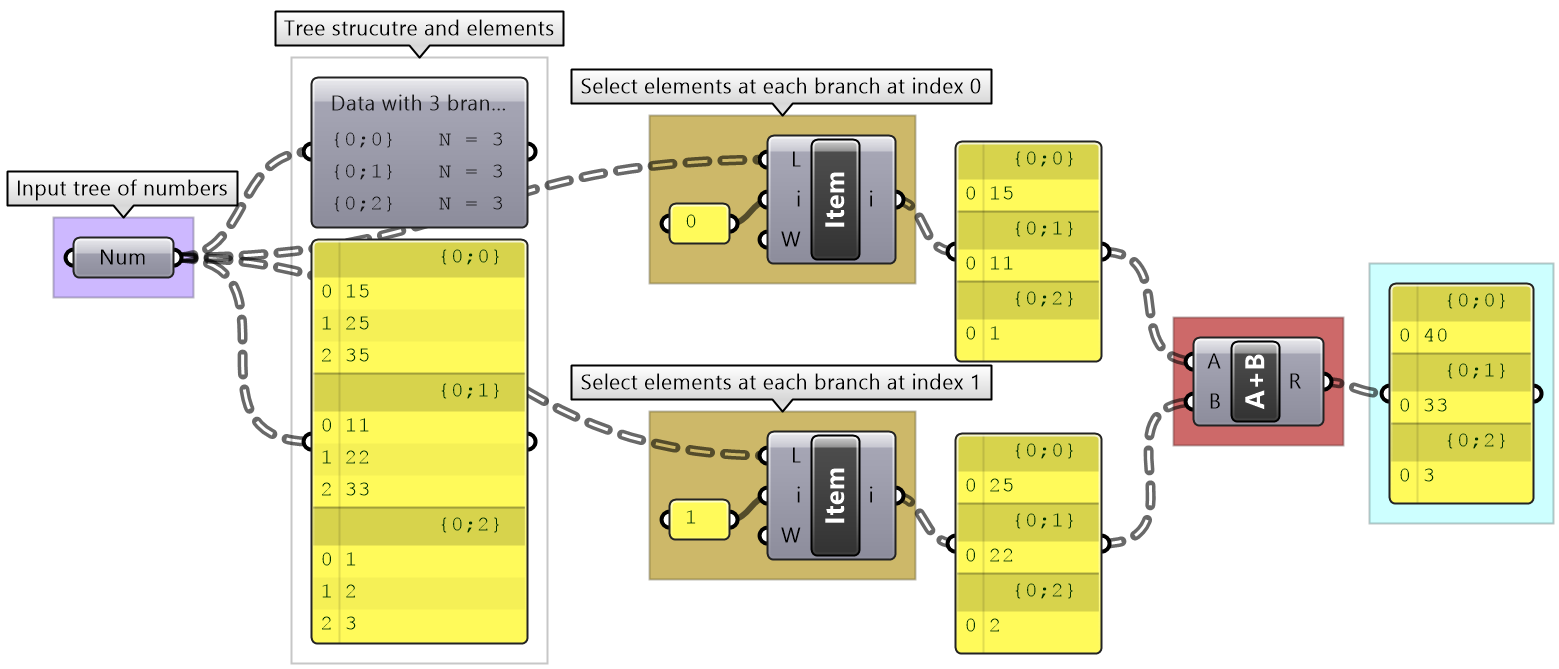
|
List Item: Select multiple indices to isolate part of the tree and perform one operation on such as Mass Addition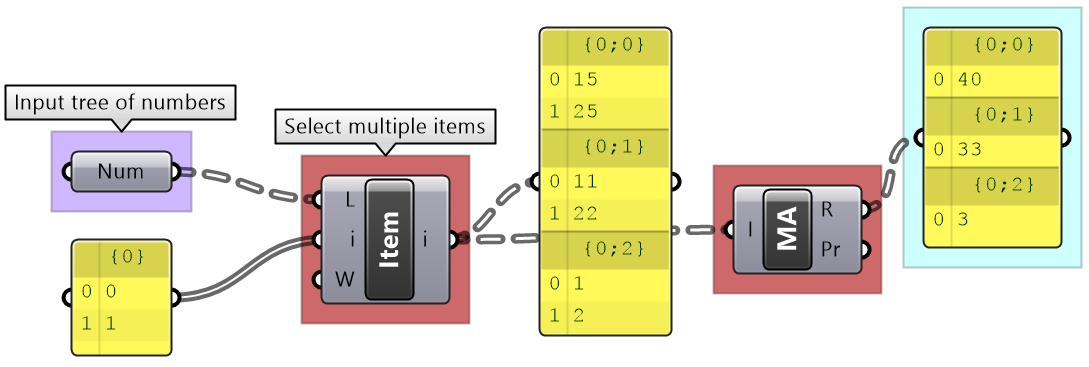
|
Split List: Split the elements of branches into 2 trees at the specified index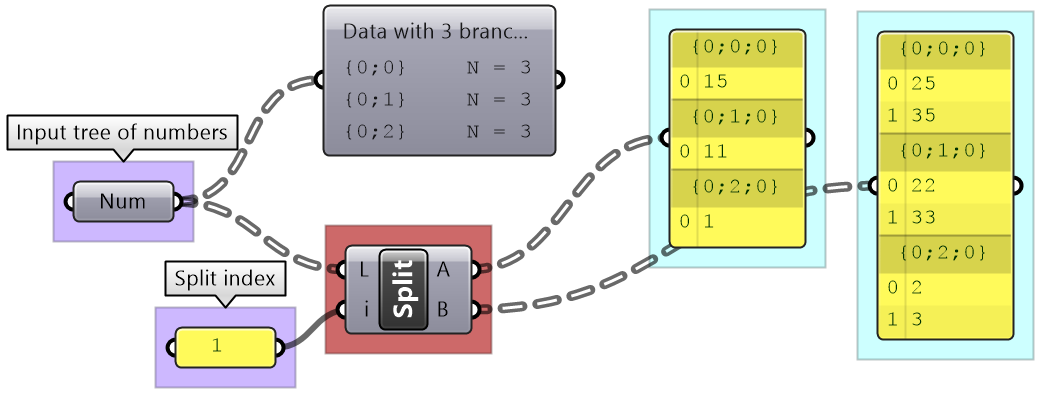
|
Shift List: Shifts the elements of each branch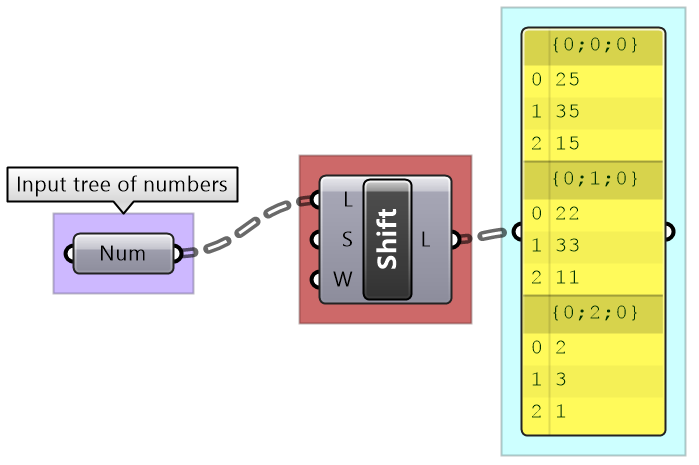
|
Cull Pattern: Culls each branch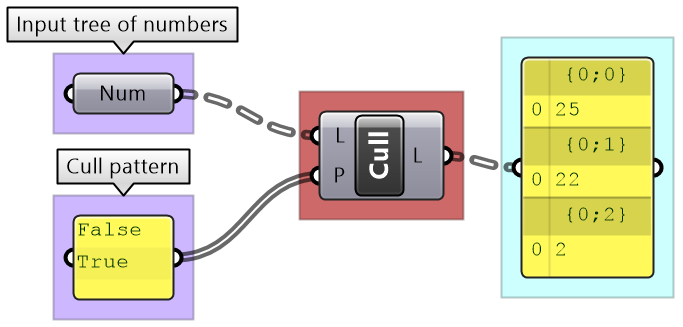
|
3.5.3 Grafting from lists to a trees
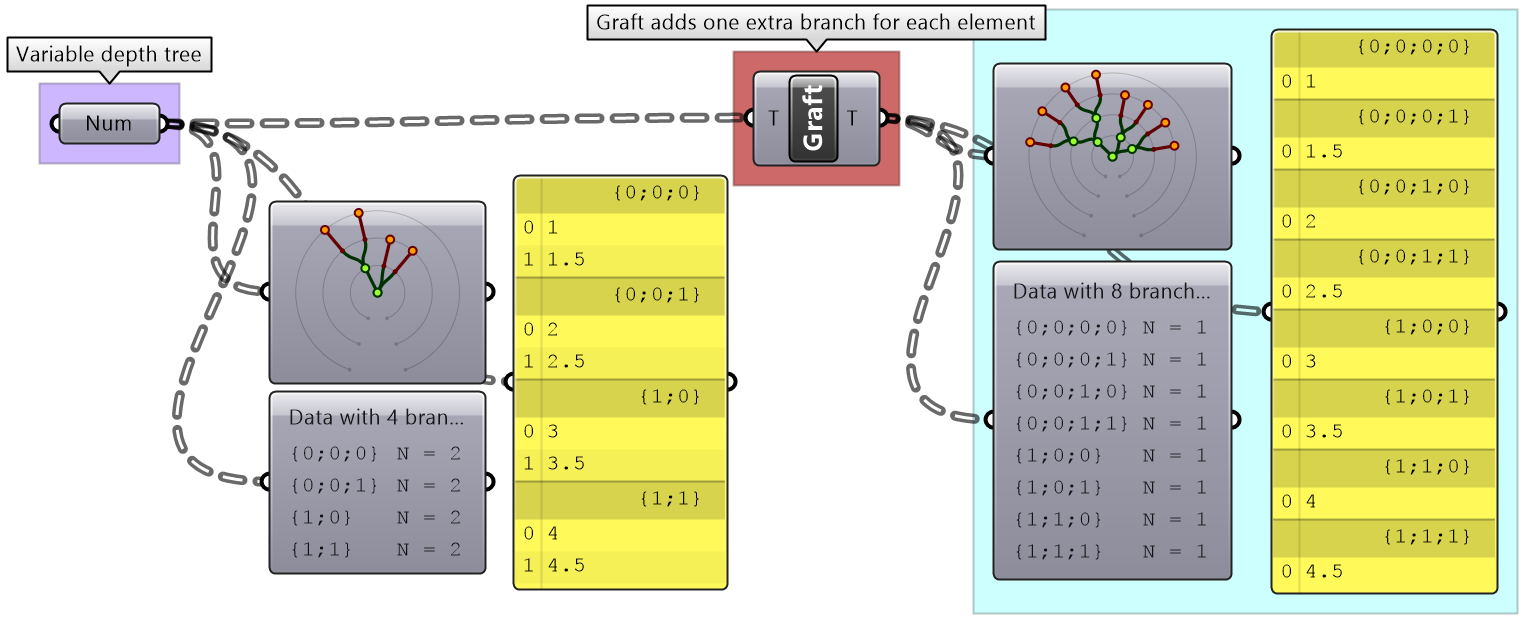
In some cases you need to turn a list into a tree where each element is placed in its own branch. Grafting can handle complex trees with branches of variable depths.
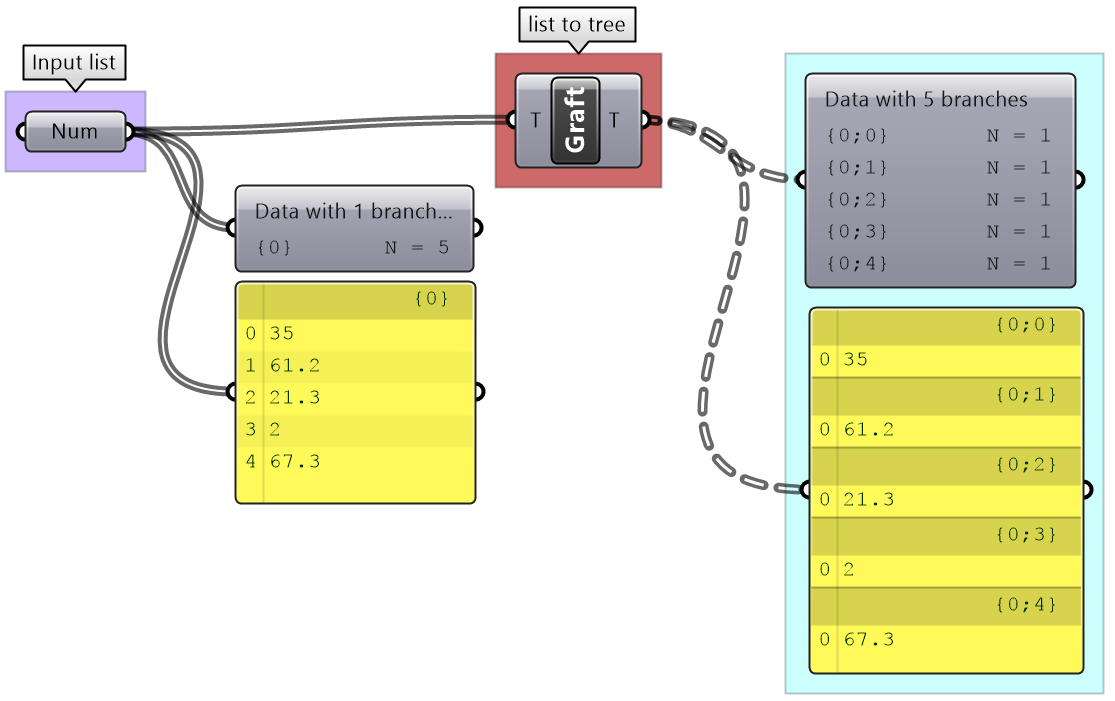
It might feel unintuitive to complicate the data structure (from a simple list to a tree), but grafting is very useful when trying to achieve certain matching. For example if you need to add each element of one list with all the elements in the second list, then you will need to graft the first list before inputting to the addition process.
3.5.4 Flattening from trees to lists
Other times you might need to turn your tree structure into a simple list. This is achieved with the flattening process. Data from each branch is extracted and sequentially attached to one list.
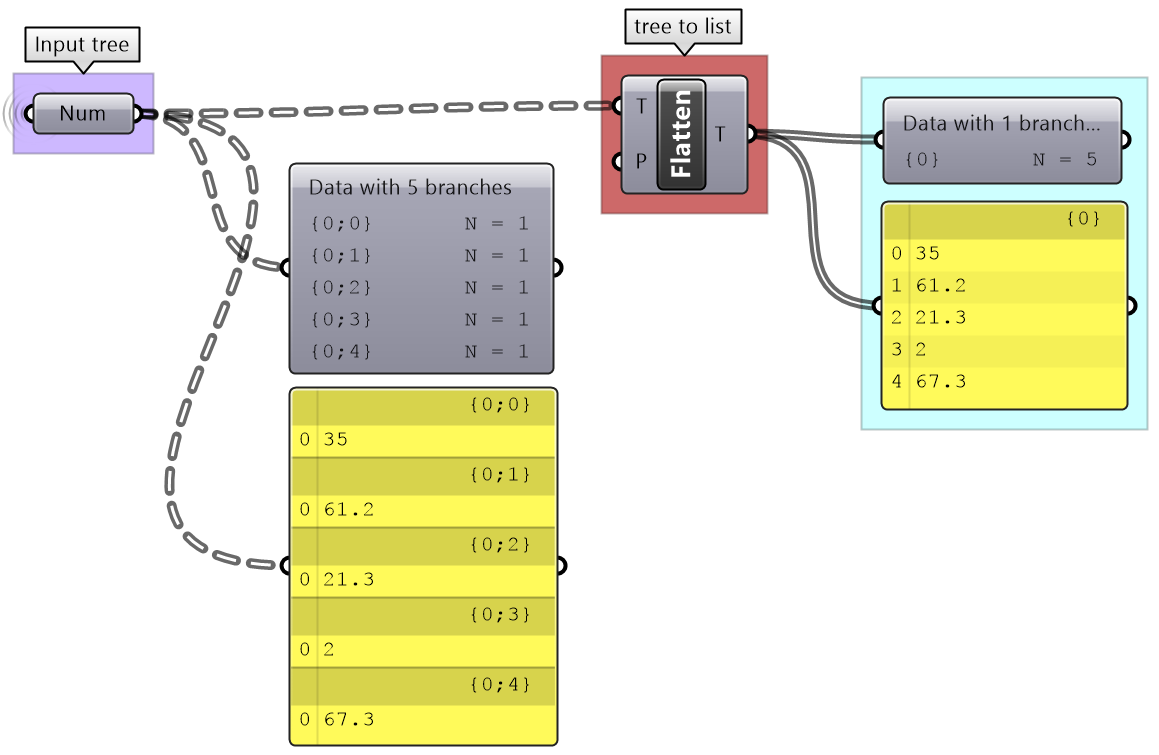
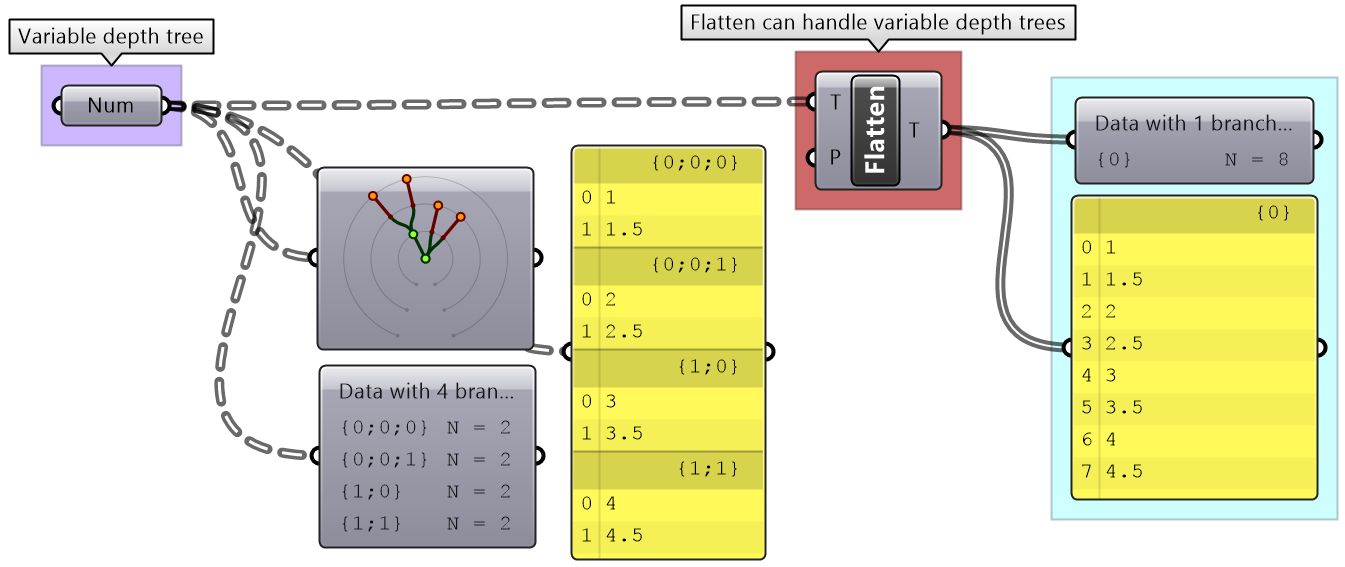
Flatten also can handle any complex tree. It takes the branches in order starting with the lowest index trunk and put all elements in one list.
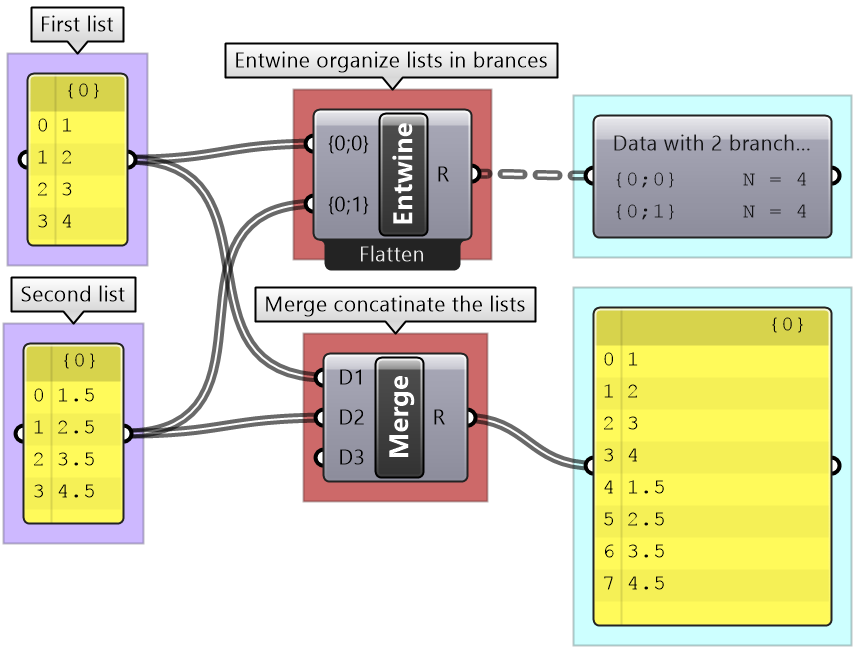
3.5.5 Combining data streams
It is possible to compose a number of lists into a tree where each list becomes a branch in a new tree. It is different from the merging of lists where simply one bigger list is created.
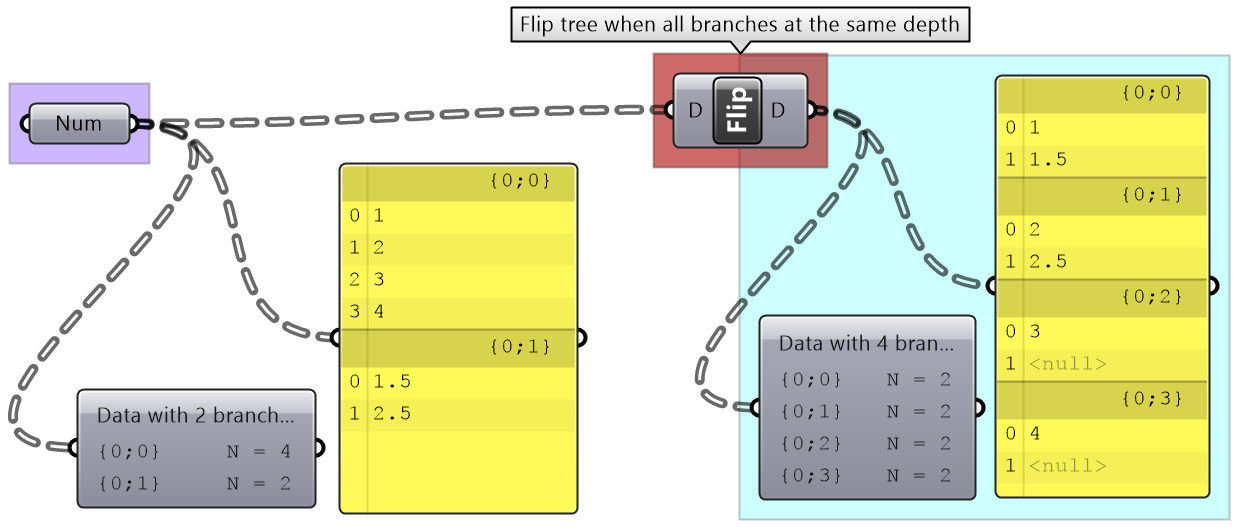
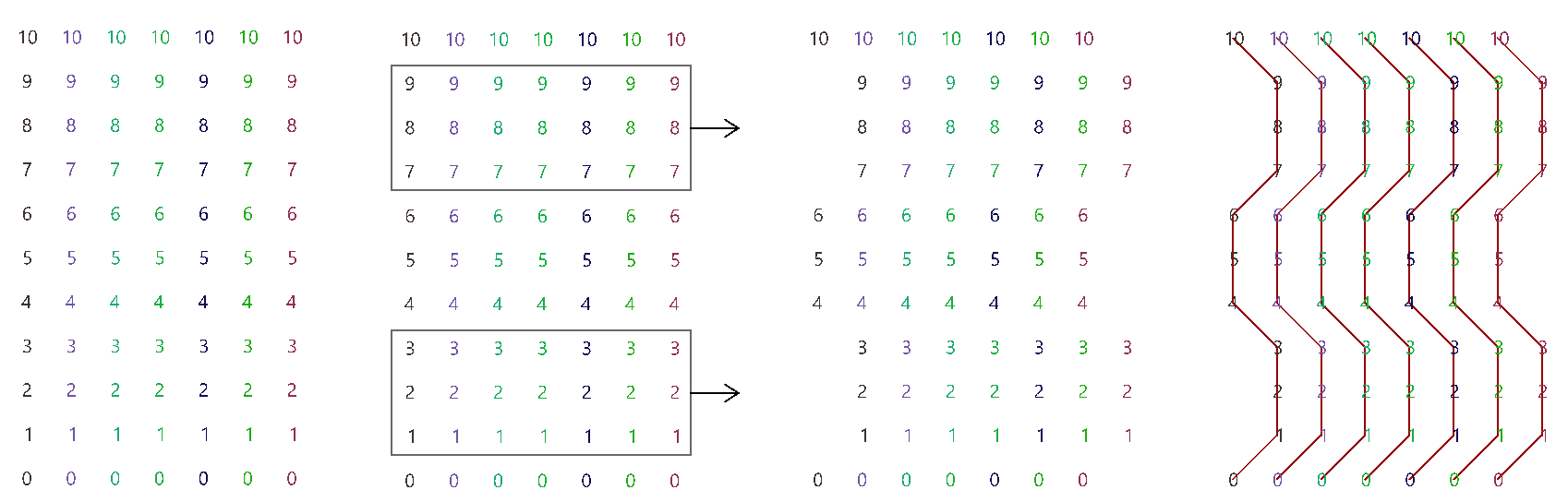
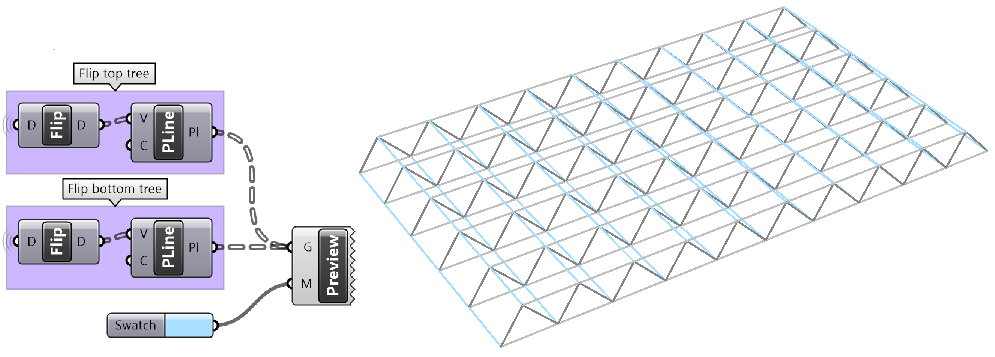
3.5.6 Flipping the data structure
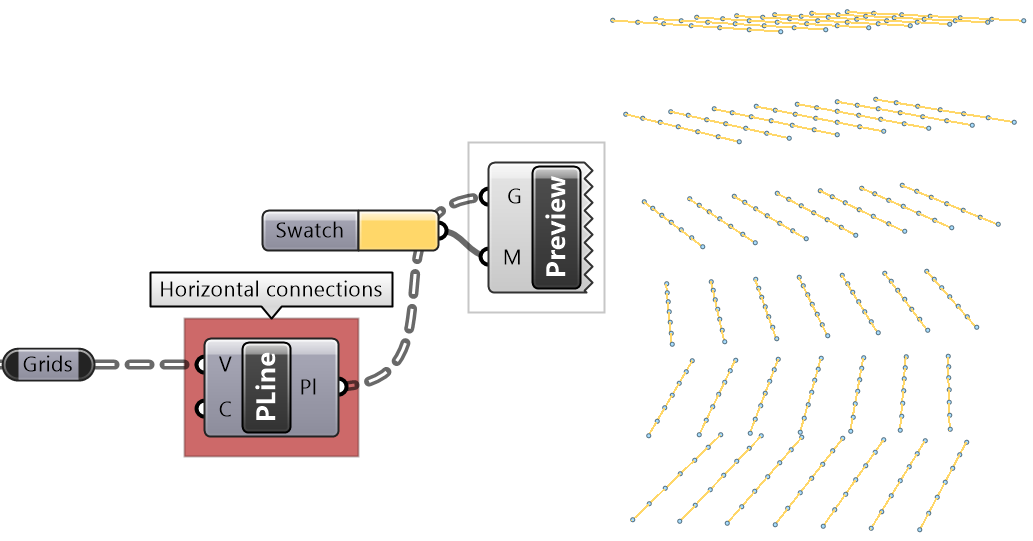
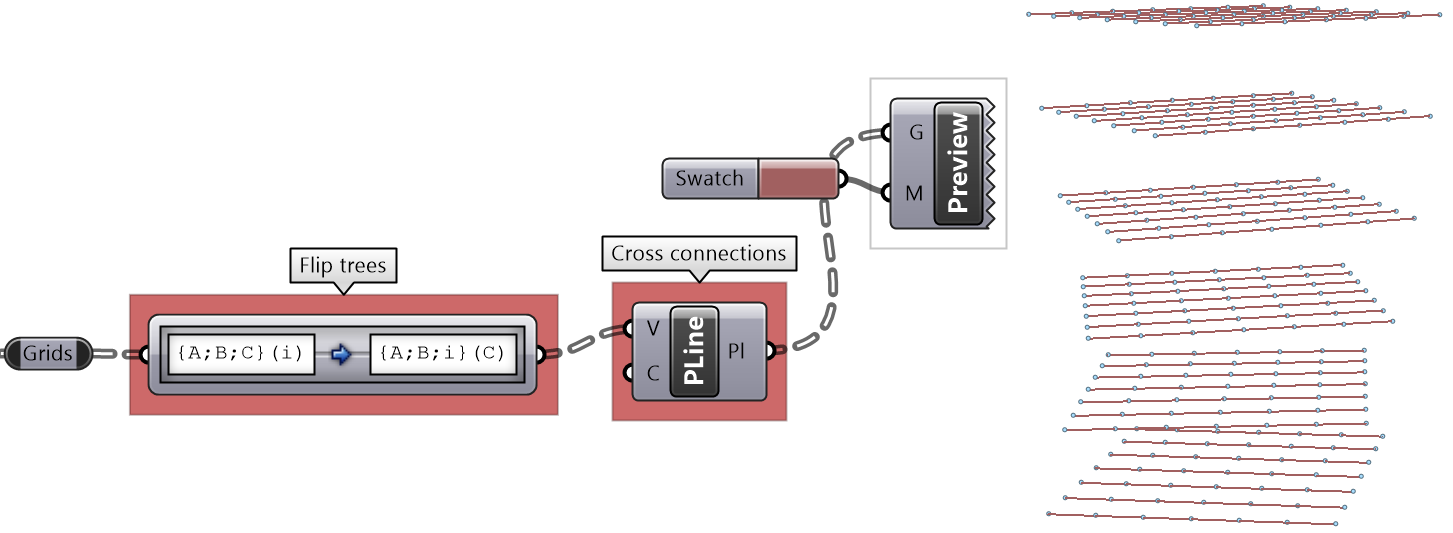
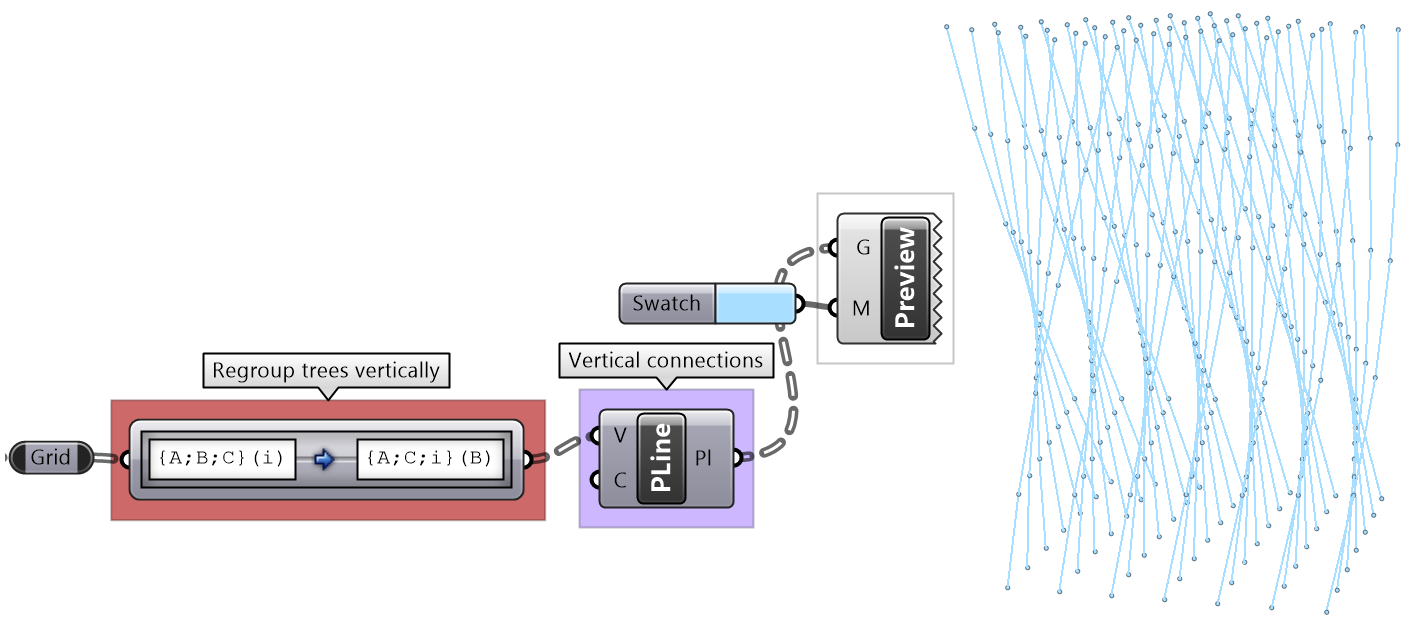
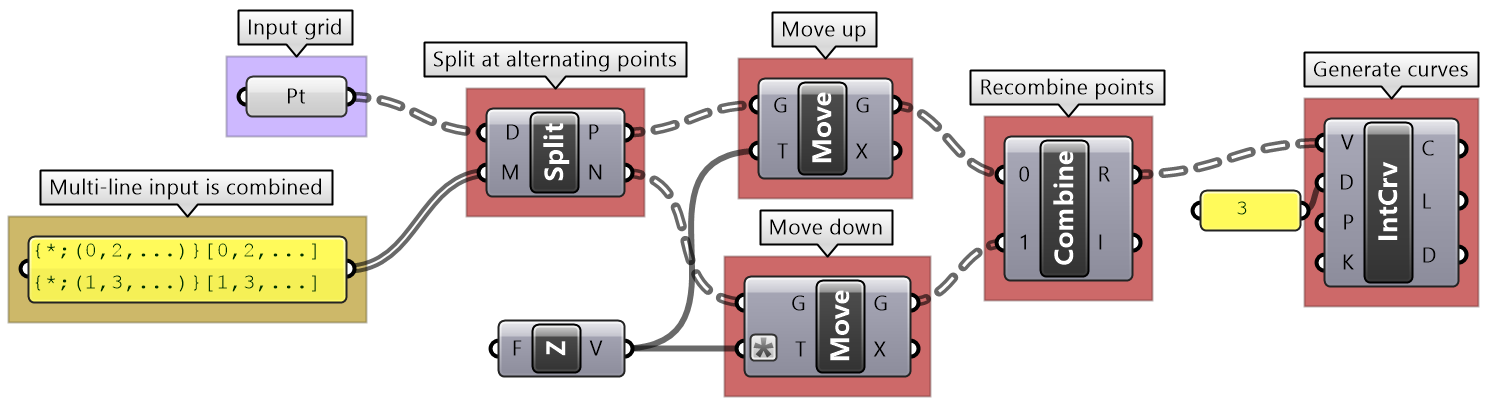
It is logical in some cases to flip the tree to change the direction of branches.This is specially useful in grids when points are organized in rows and columns (similar to a 2 dimensional array structure). Flipping causes corresponding elements across branches (have the same index in their branch) to be grouped in one branch. For example, a data tree that has 2 branches and 4 items in each branch, can be flipped into a tree with 4 branches and 2 elements in each branch.
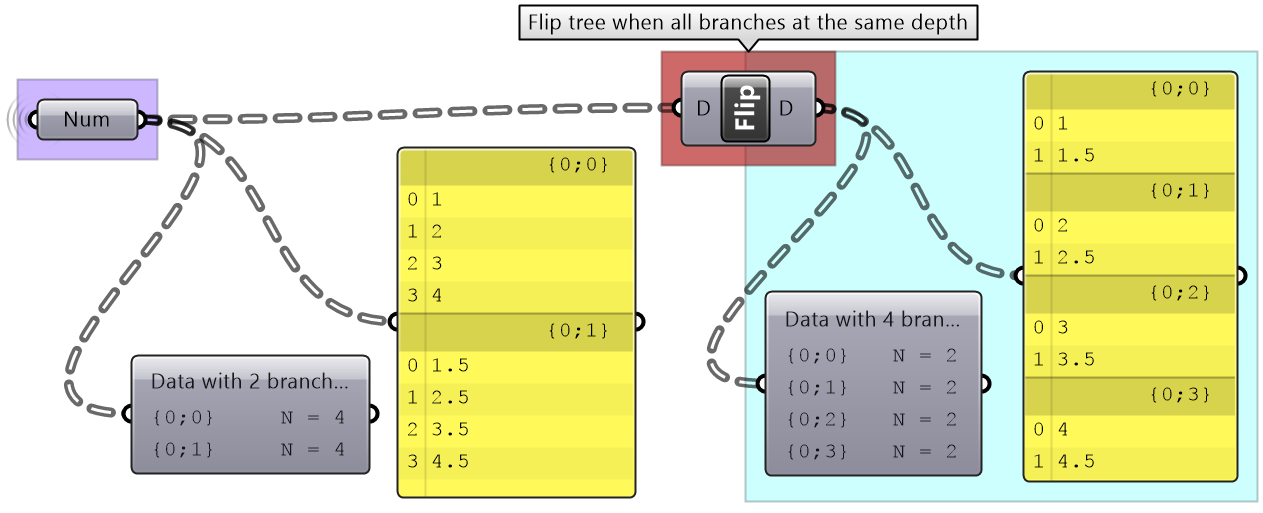
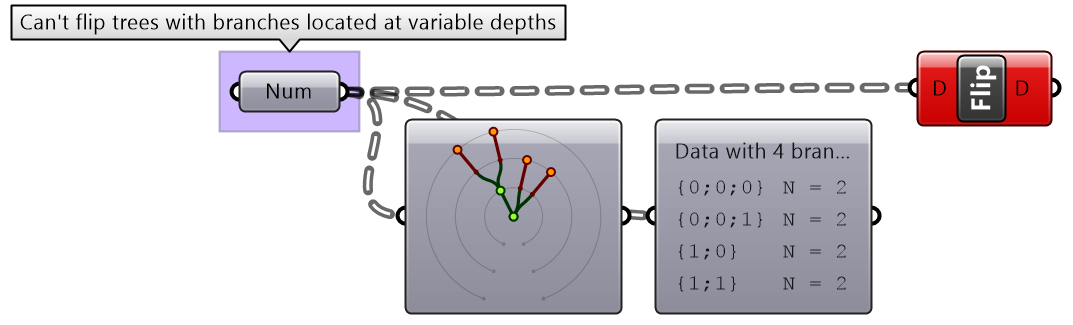
If the number of elements in the branches are variable in length, some of the branches in the flipped tree will have “null” values.
Flipping is one of the operations that cannot handle variable depth branches, simply because there is no logical solution to flip.
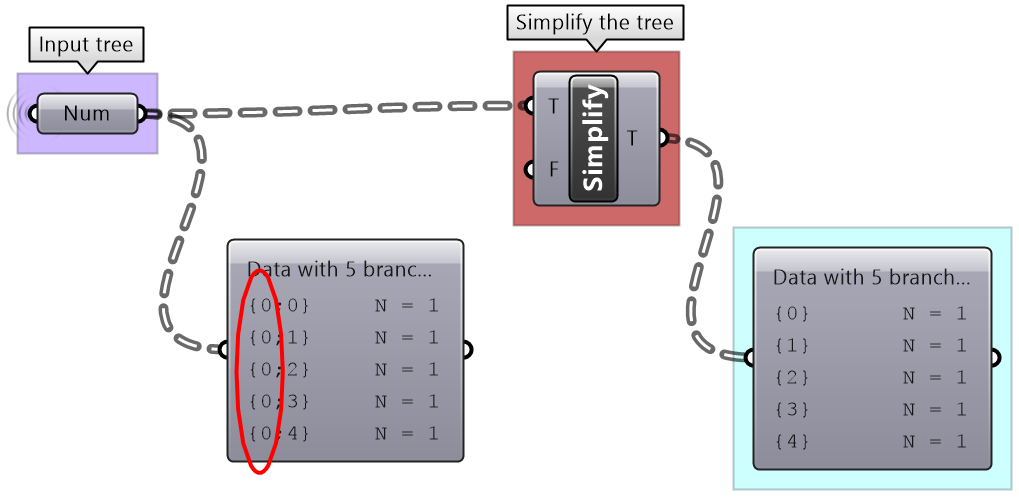
3.5.7 Simplifying the data structure
Processing data through multiple components can add unnecessary complexity to the data structure. The most common form is adding leading or trailing zeros to the paths addresses. Complex data structures are hard to match. Simplify Tree process helps remove empty branches. There are other operations such as Clean Tree and Trim Tree to help remove null elements, empty branches and reduce complexity. It is also possible to extract all branches as separate lists using the Explode Tree operation.
| Tutorial 3.5.A Louvers | |||||||
|---|---|---|---|---|---|---|---|
Given one curve on XY-Plane, create horizontal and vertical louvers as in the image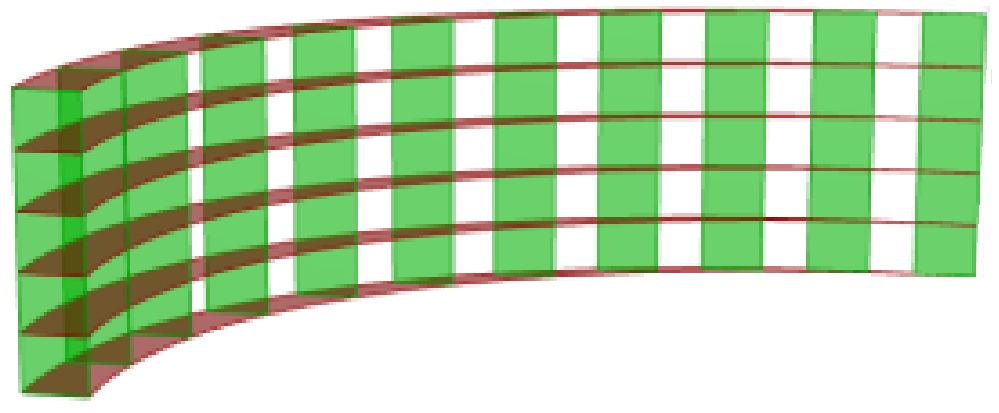
|
|||||||
Solution...
|


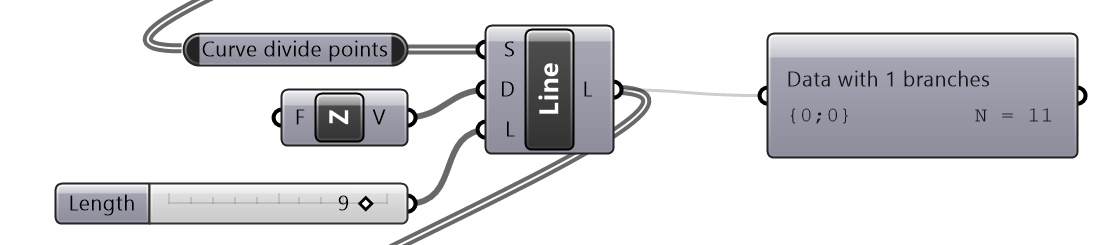
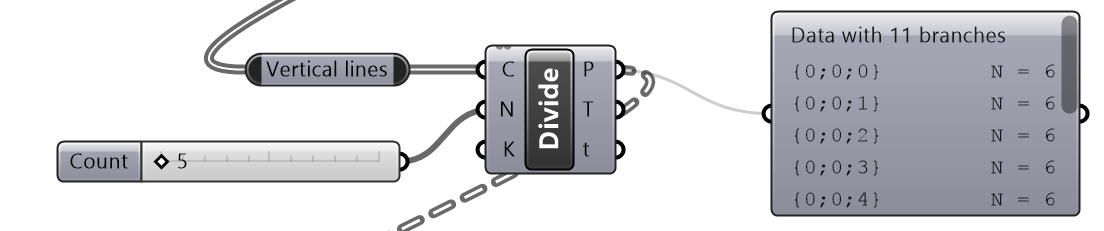
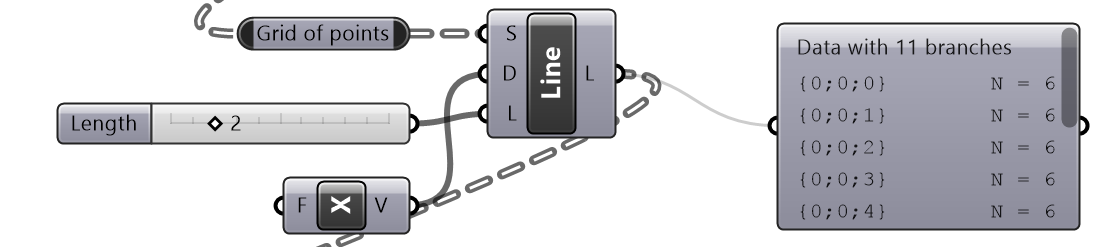

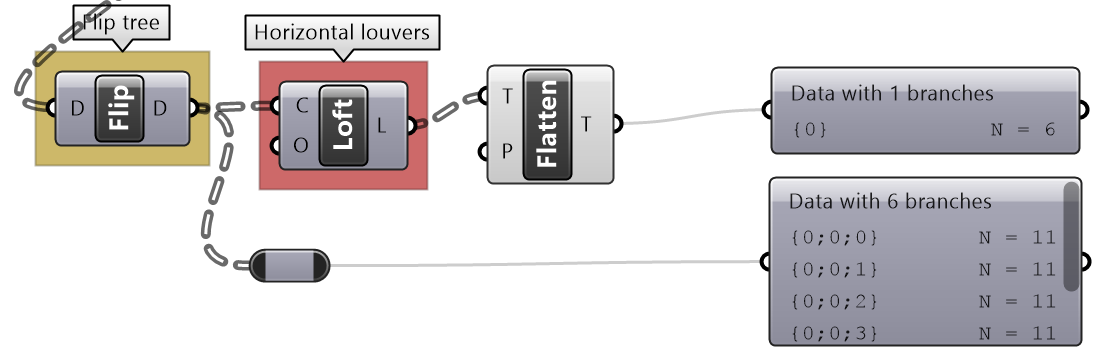
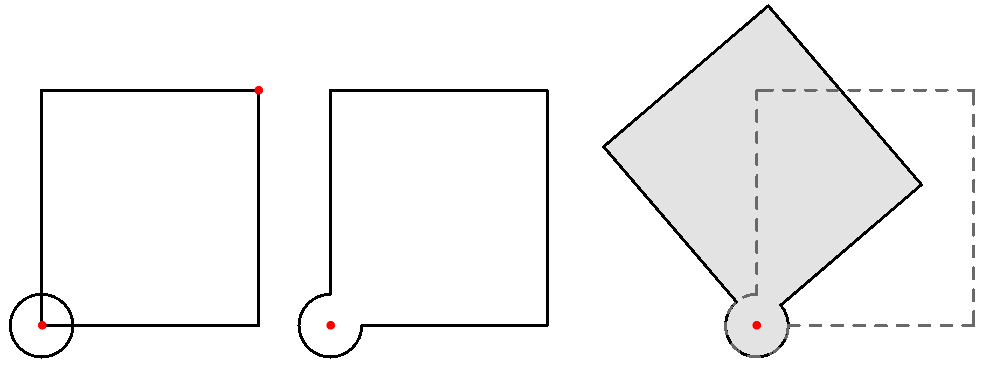
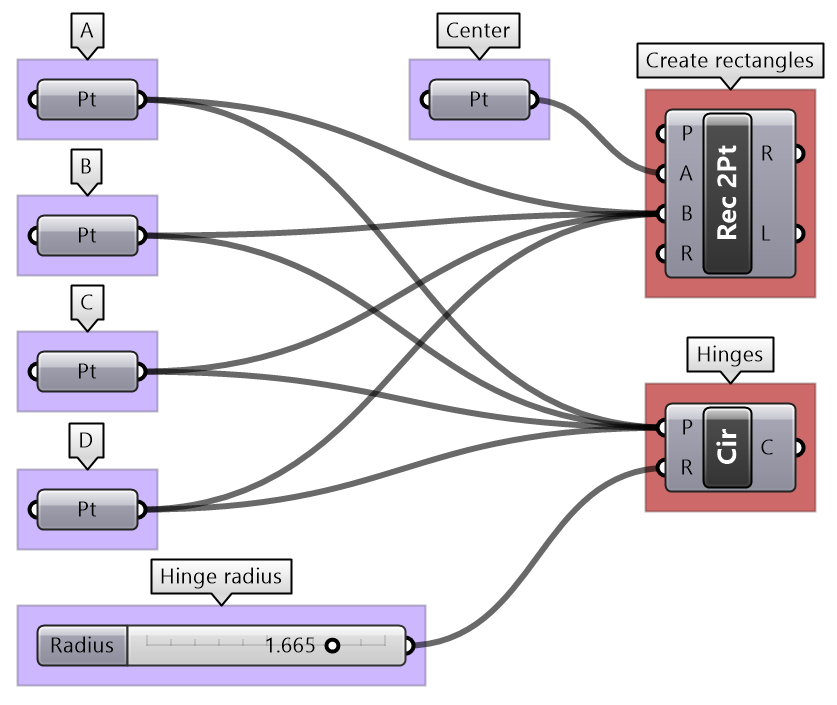
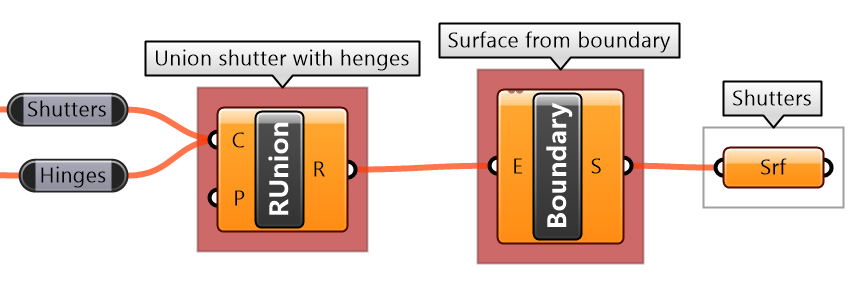
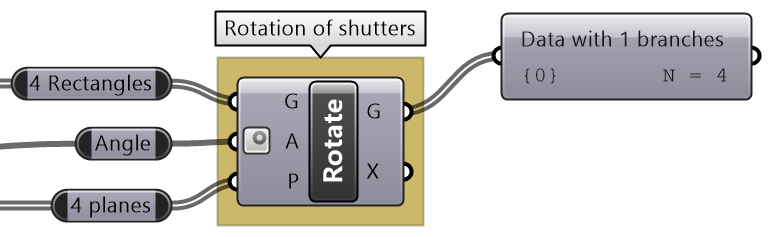
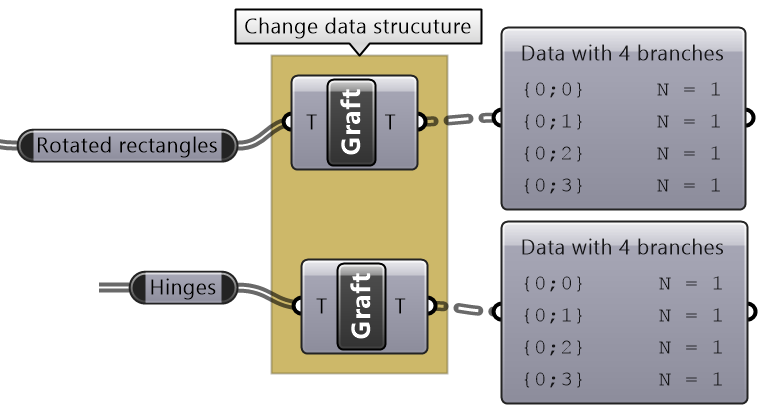
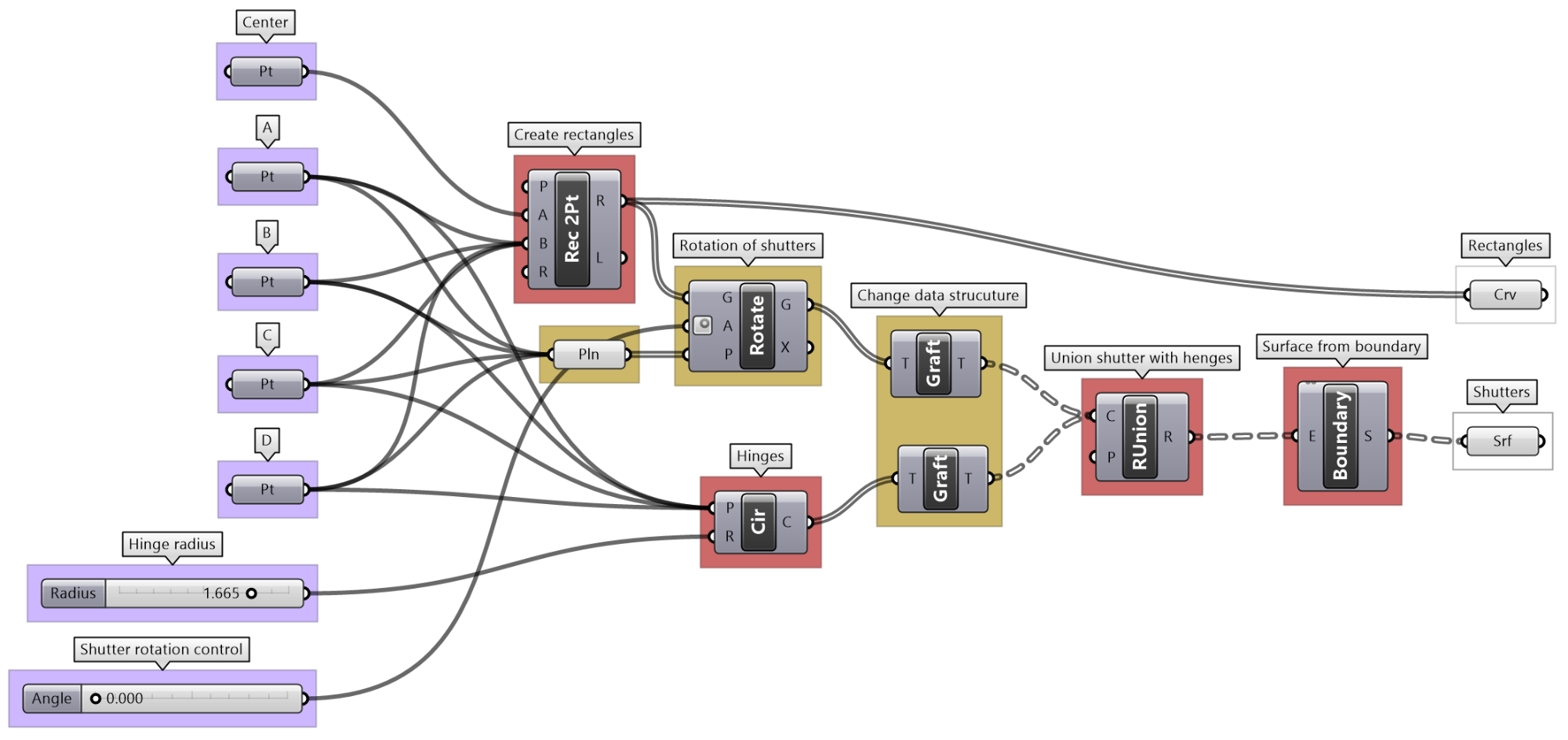
| Tutorial 3.5.B Shutters | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
Given four corner points on a plane and a radius for the hinge, create a shutter that can open and shut as in the image using a rotation parameter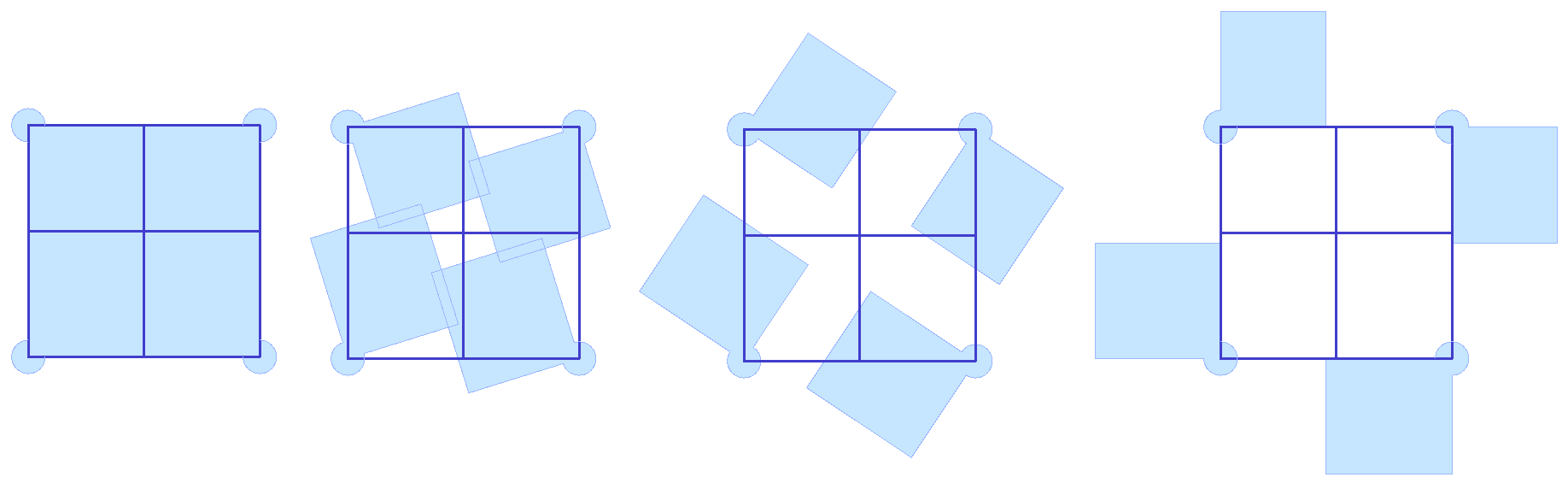
|
||||||||||
Solution...
|
3.6 Advanced tree operations
As your solutions increase in complexity, so will your data structures. We will discuss three advanced tree operations that are necessary to solve specific problems, or are used to simplify your solution by tabbing directly into the power of the data tree structure.
3.6.1 Relative items
Advanced data trees operations: Relative item
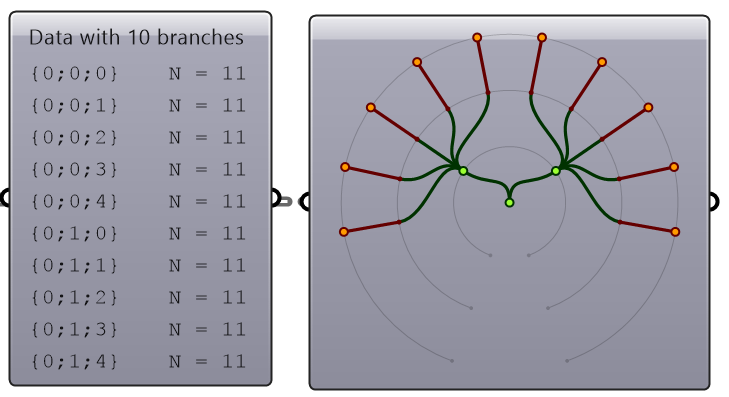
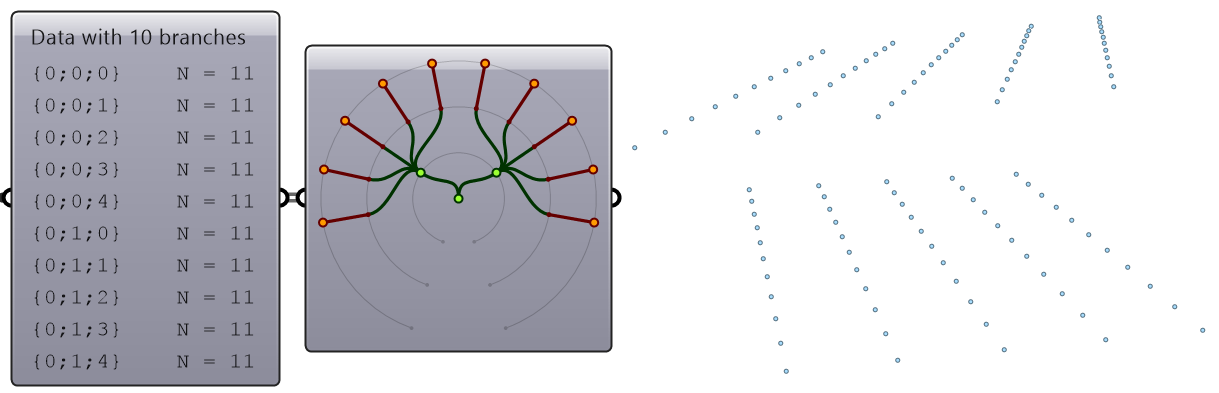
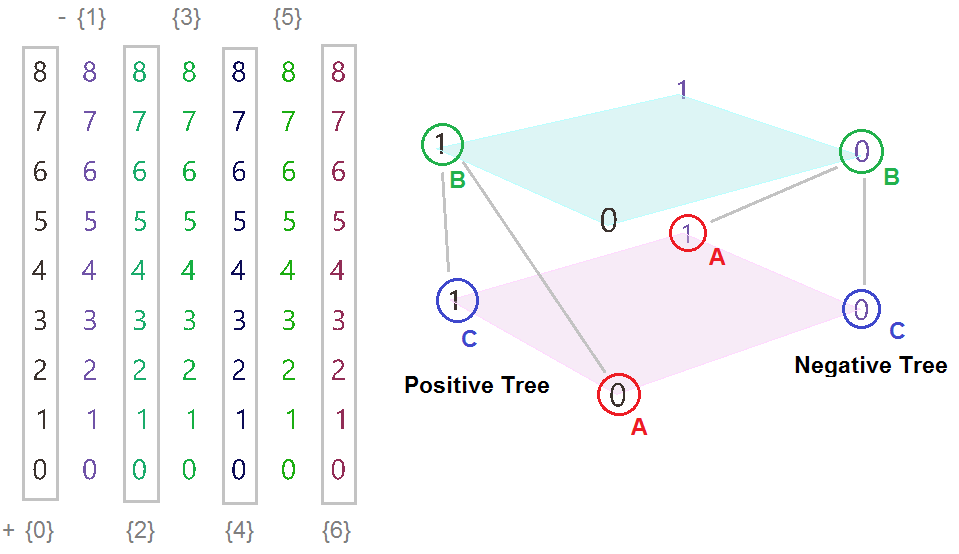
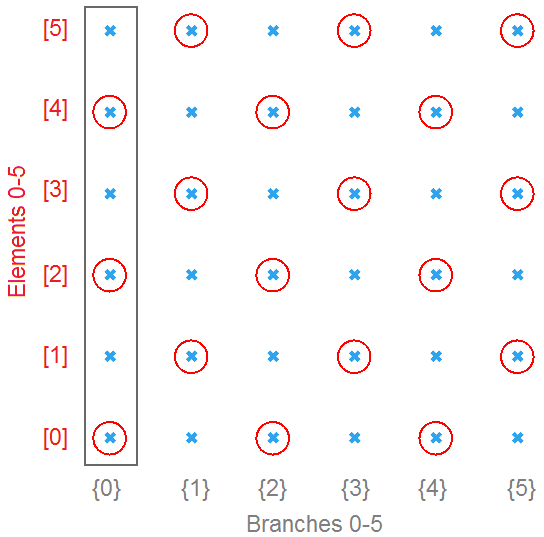
The first operation has to do with solving the general problem of connectivity between elements in one tree or across multiple trees. Suppose you have a grid of points and you need to connect the points diagonally. For each point, you connect to another in the +1 branch and +1 index. For example a point in branch {0}, index [0], connects to the point in branch {1}, index [1].
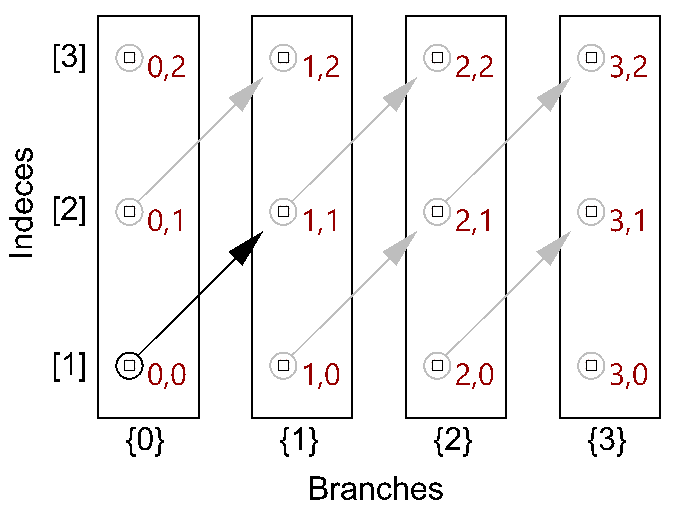
In Grasshopper, the way you communicate the offset is expressed with an offset string in the format “{branch offset}[index offset]”. In our example, the string to connect points diagonally is “{+1}[+1]”. Here is an example that uses relative tree component in Grasshopper. Notice that the relative item component creates two new trees that correlate in the manner specified in the offset string.
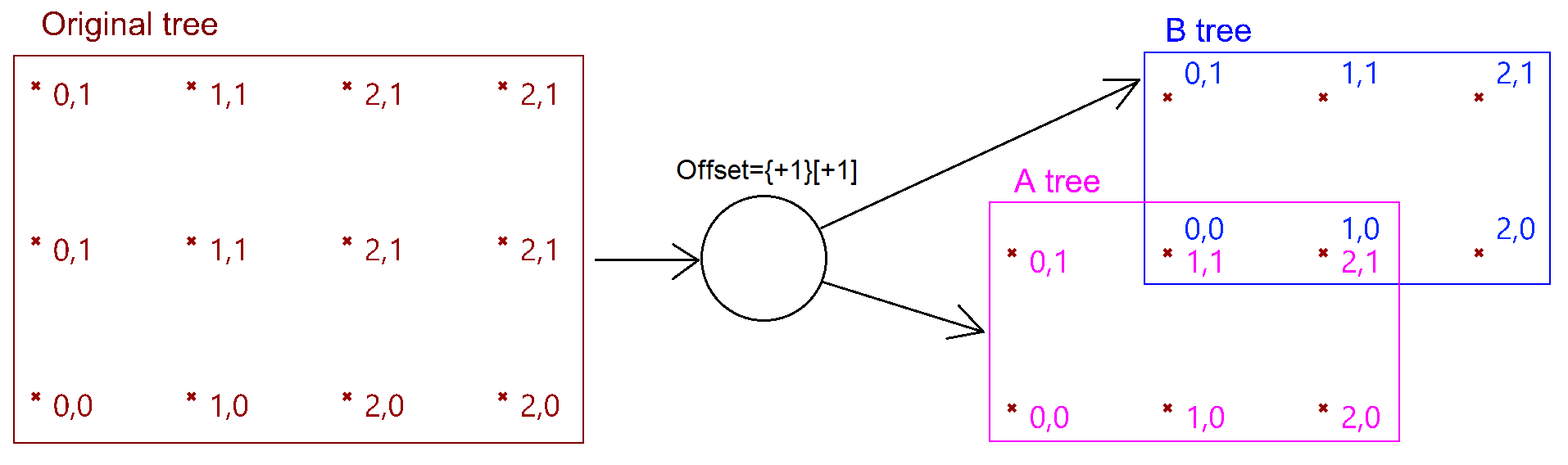
Here is an example implementation in Grasshopper where we define relative items in one tree, then connect the two resulting trees with lines using the Relative Item component.
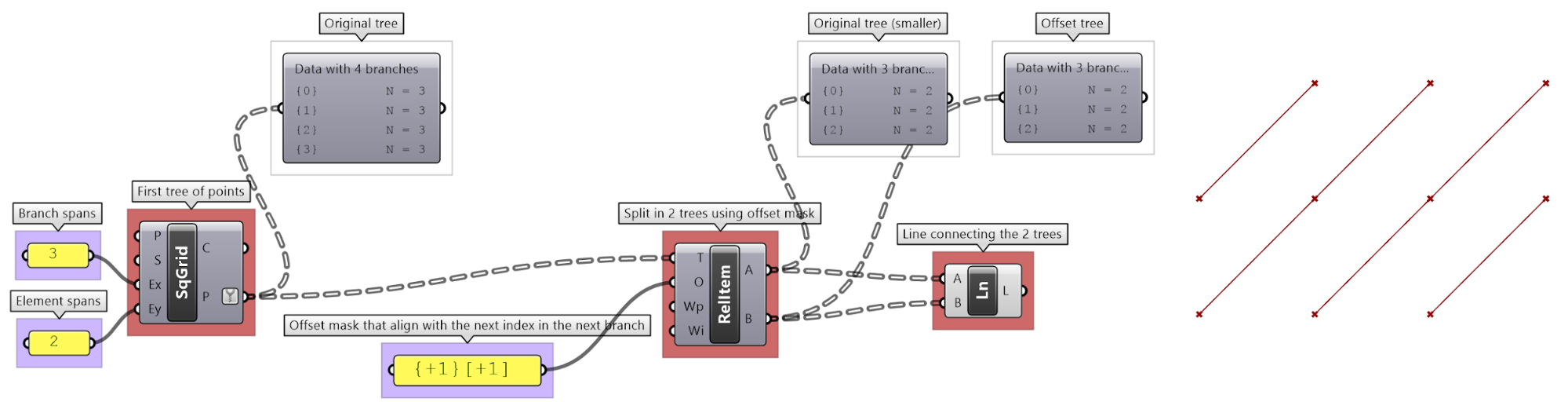
| Tutorial 3.6.1.A Relative item pattern | |||
|---|---|---|---|
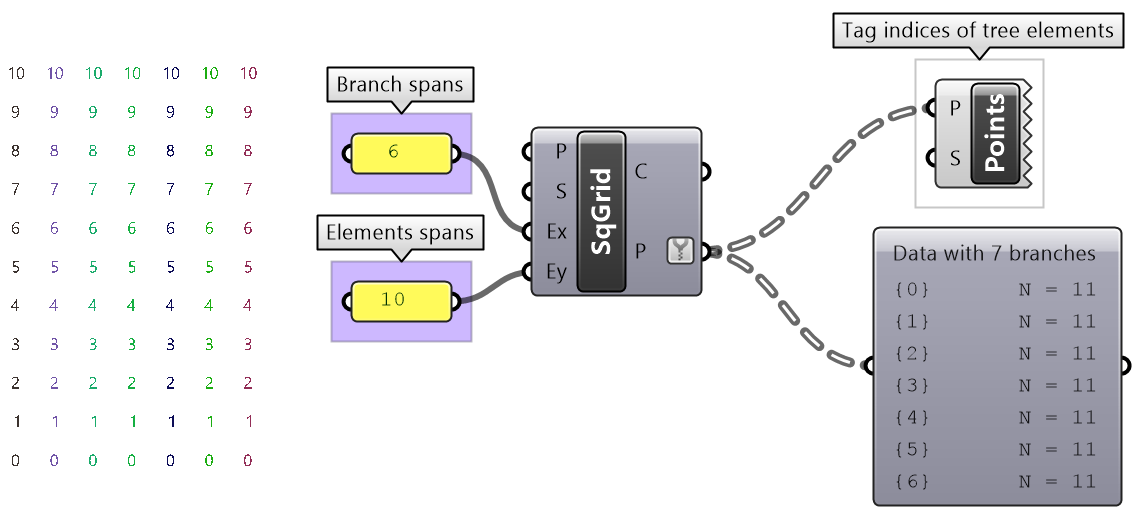
Create the pattern shown in the image using a square grid of 7 branches where each branch has11 elements.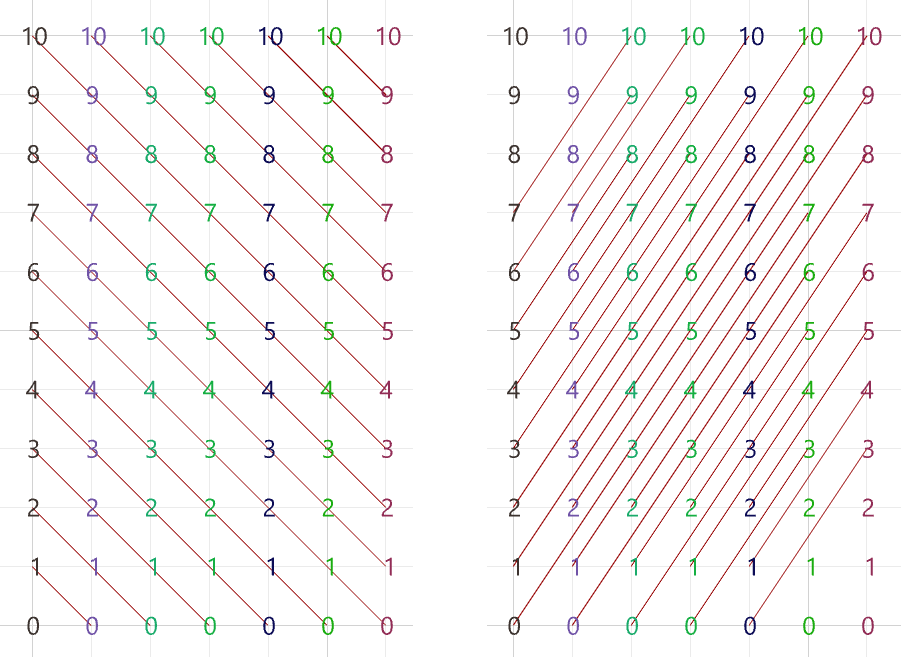
|
|||
Solution...
|
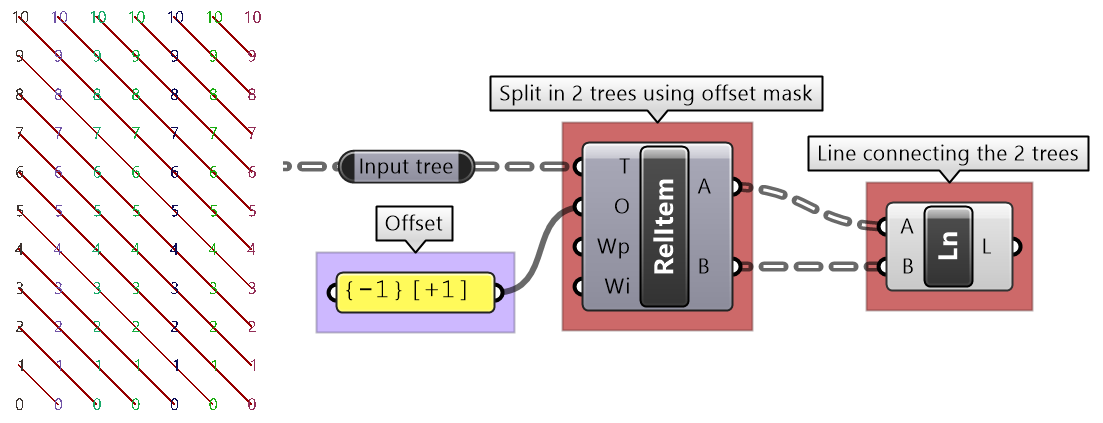
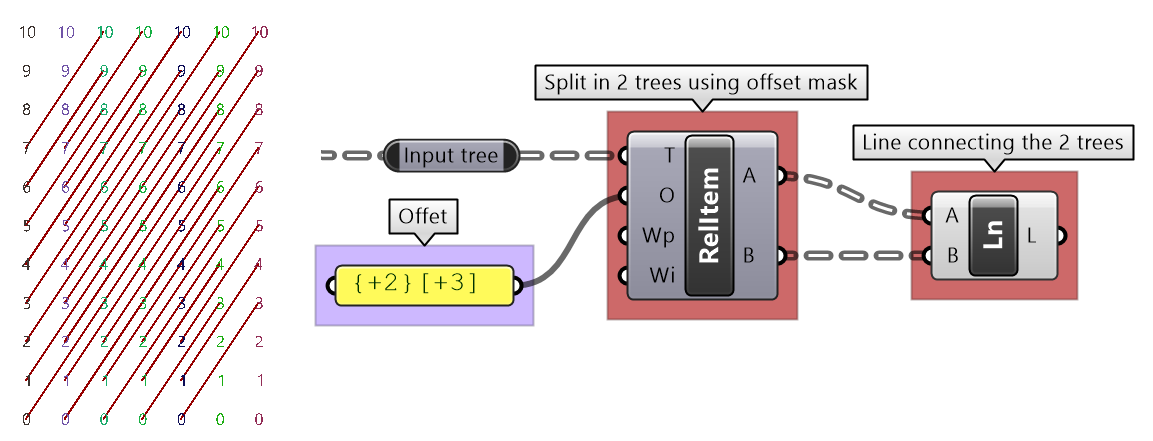
We showed how to define relative items in one tree, but you can also specify relative items between 2 trees. You’ll need to pay attention to the data structure of the two input trees and make sure they are compatible. For example, if you connect each point from the first tree with another point from a different tree with the same index, but +1 branch, then you can set the offset string to be {+1}[0].
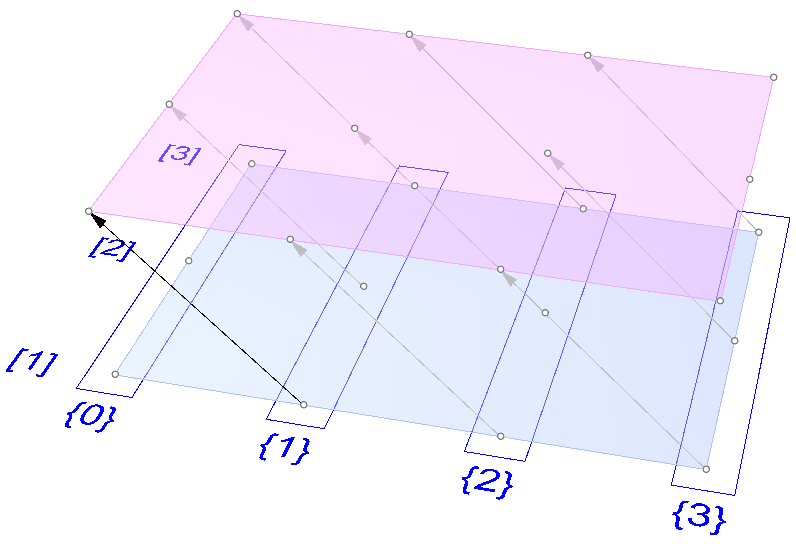
The input to the Relative Items component is two trees and the output is two trees with corresponding items according to the offset string.
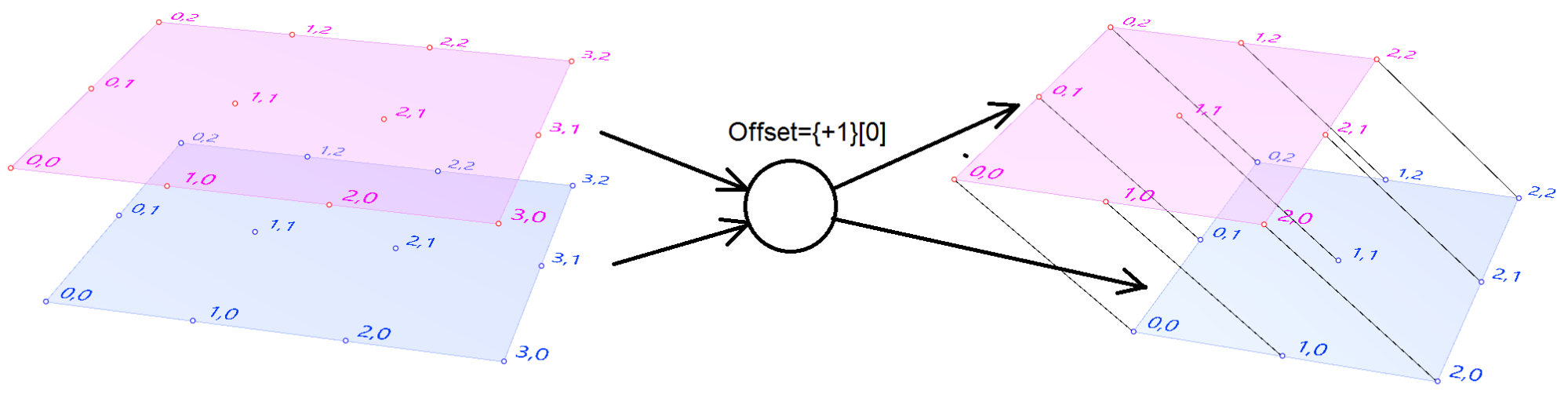
The following GH definition achieves the above:
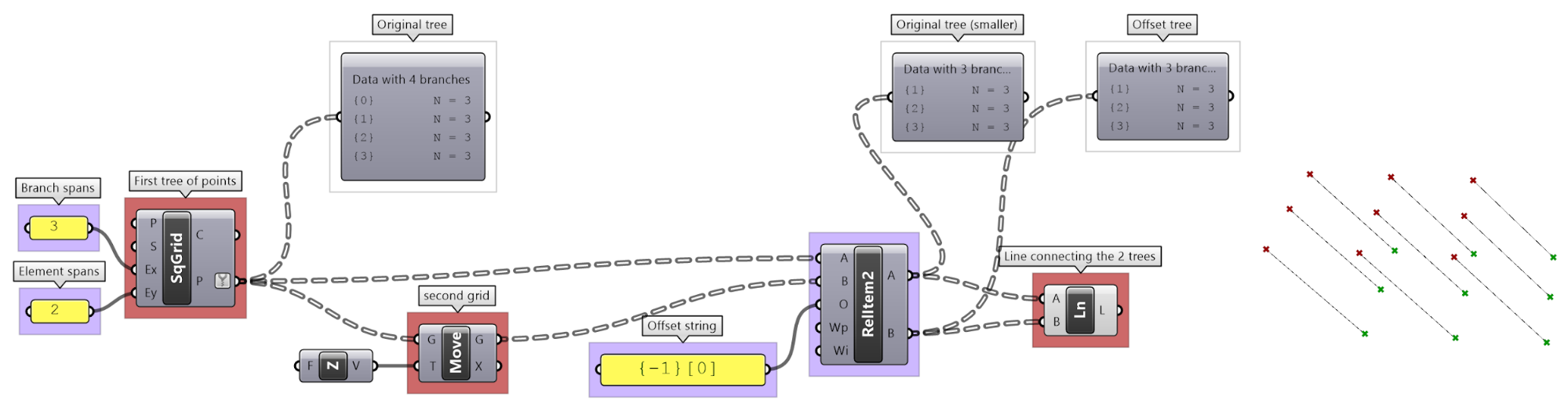
| Tutorial 3.6.1.B Relative item truss | ||||||
|---|---|---|---|---|---|---|
Use relative items between 2 bounding grids to generate the structure shown in the image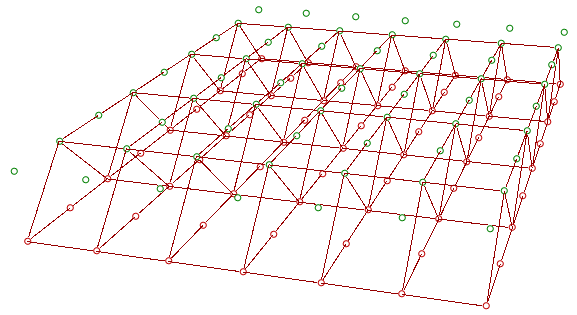
|
||||||
Solution...Solution video...
|
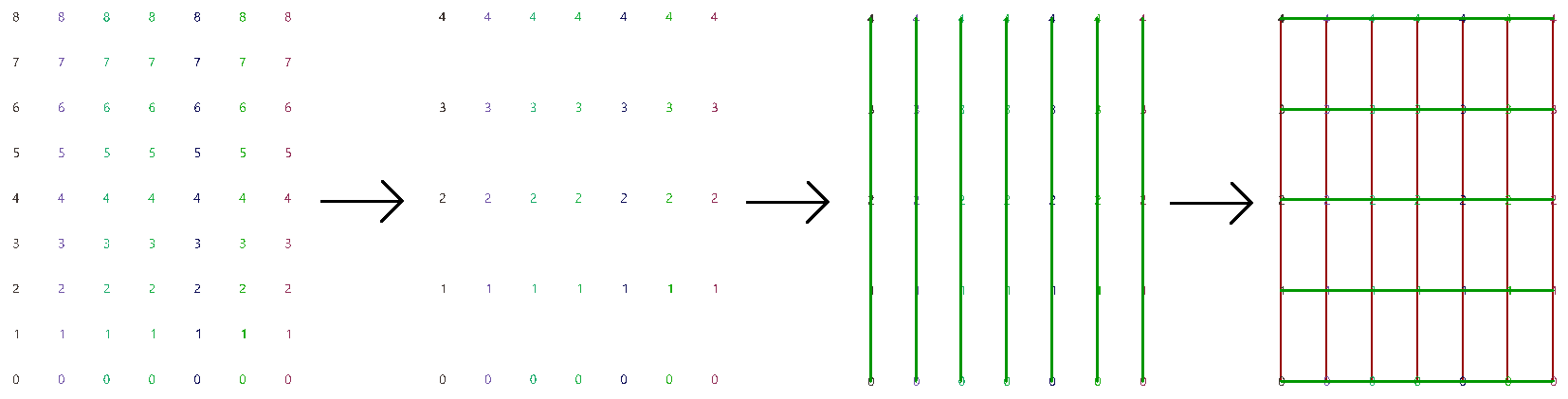
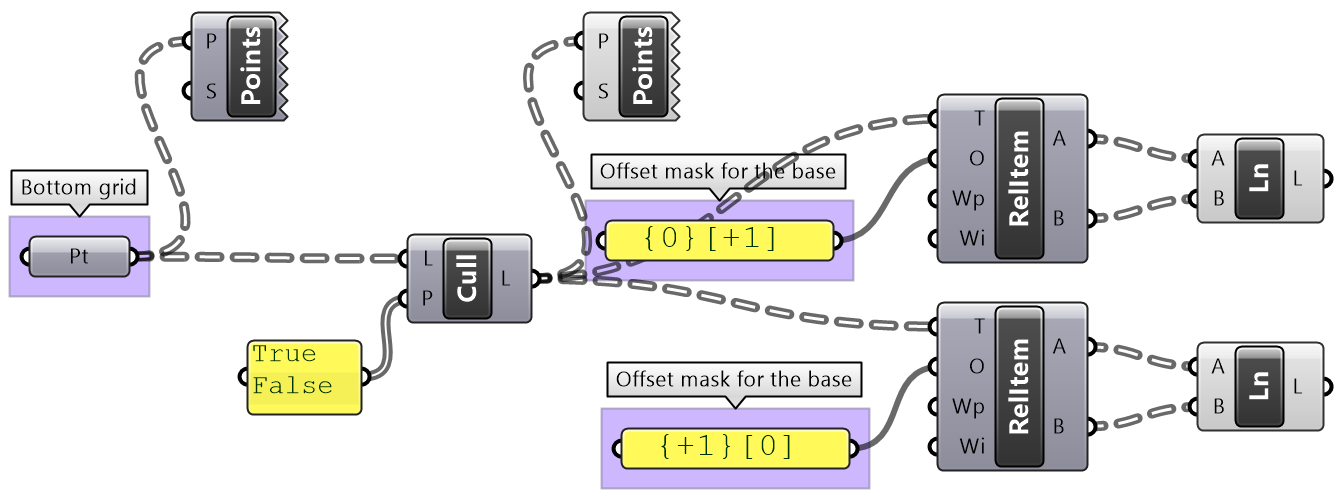
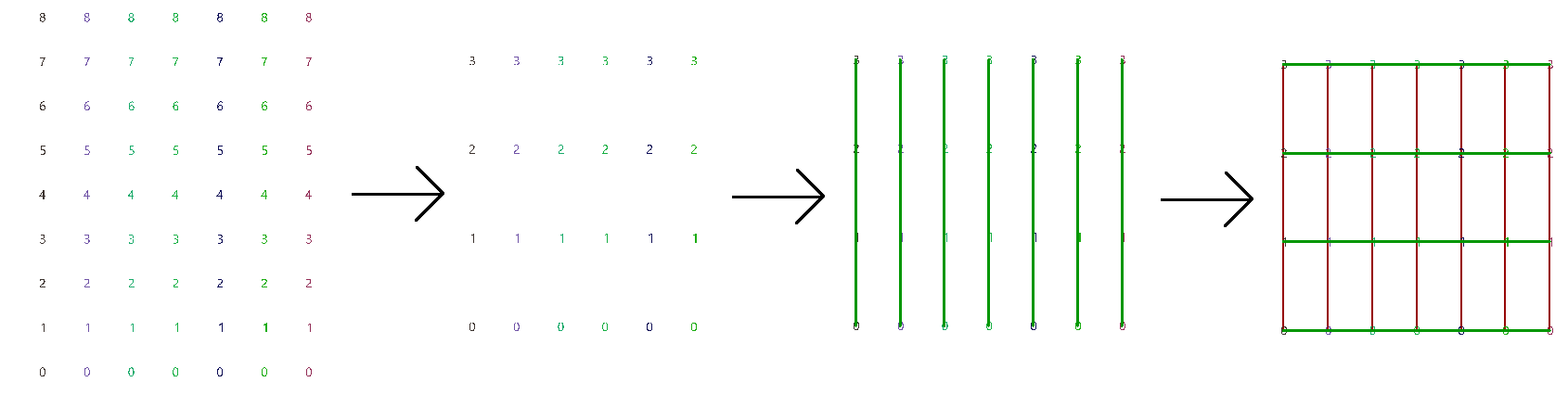
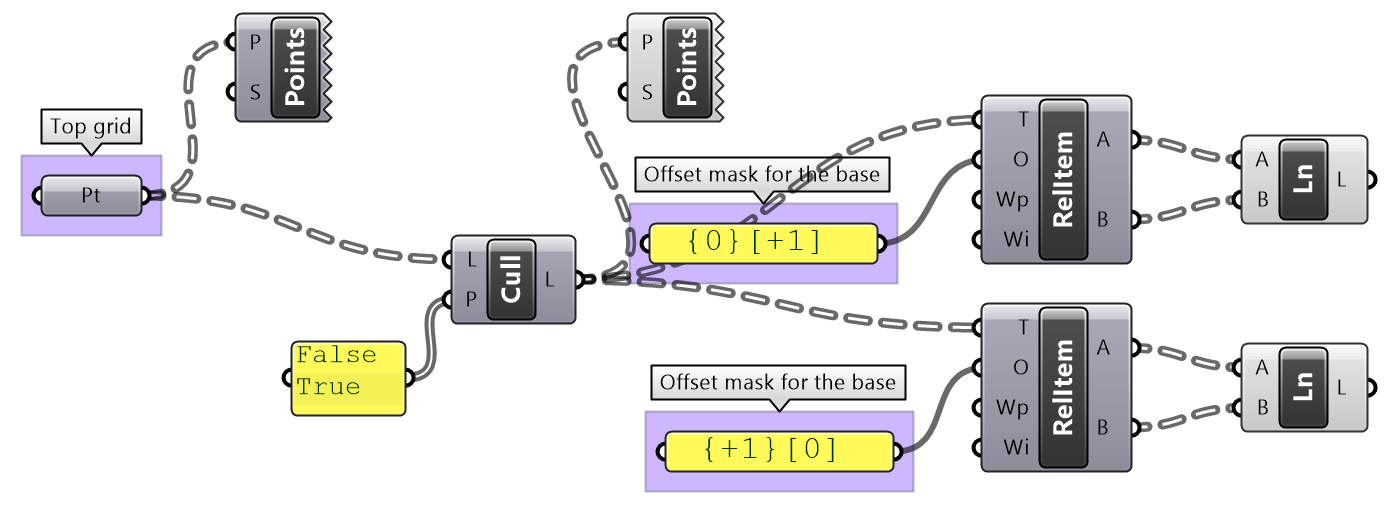
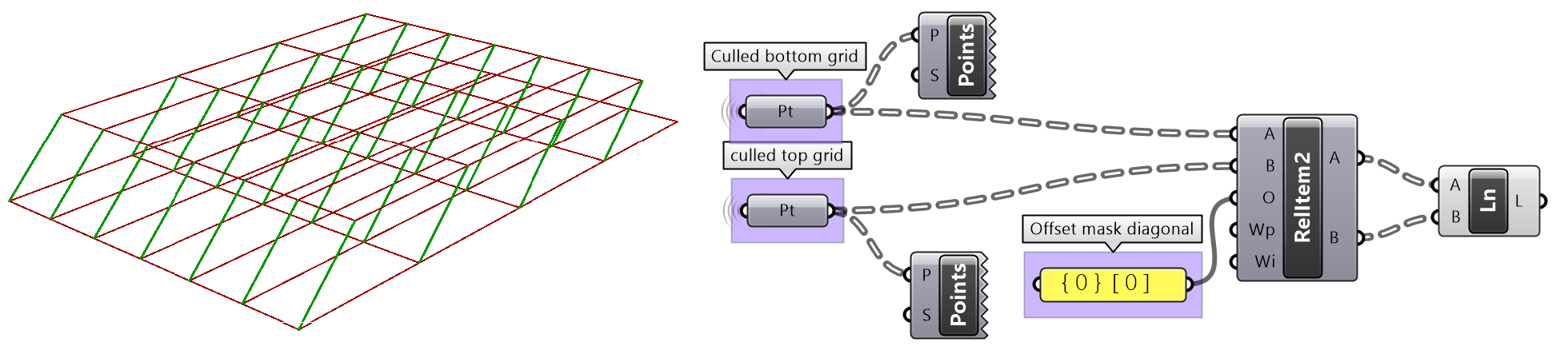
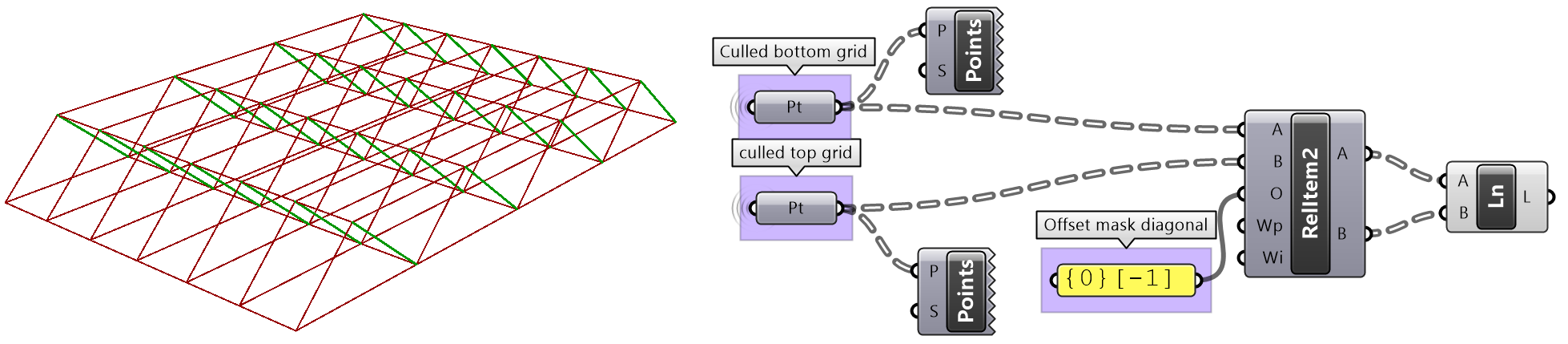
3.6.2 Split trees
The ability to select a portion of a tree, or split into two parts is a very powerful tree operation in Grasshopper. You can split the tree using a string mask using specific syntax (see examples below). The mask filters, or helps select, the positive part of your tree. The portion of the tree left, is also given as an output and is called the negative part of the tree. Since all trees are made out of branches and indices, the split mask should include information about which branches and indices within these branches to split along. Here are the rules of the split mask:
| Mask syntax | General rules |
|---|---|
| { ; ; } | Use curly brackets to enclose the mask for the tree branches. |
| [ ] | Use square brackets to enclose the mask for the elements (leaves). Can be omitted if select all items or use [*] |
| ( ) | Round brackets are used for organizing and grouping |
| * | Any number of integers in a path. The asterisk also allows you to include all branches, no matter what their paths look like |
| ? | Any single integer |
| 6 | Any specific integer |
| !6 | Anything except a specific integer |
| (2,6,7) | Any one of the specific integers in this group. |
| !(2,6,7) | Anything except one of the integers in this group. |
| (2 to 20) | Any integer in this range (including both 2 and 20). |
| !(2 to 20) | Any integer outside of this range. |
| (0,2,...) | Any integer part of this infinite sequence. Sequences have to be at least two integers long, and every subsequent integer has to be bigger than the previous one (sorry, that may be a temporary limitation, don't know yet). |
| (0,2,...,48) | Any integer part of this finite sequence. You can optionally provide a single sequence limit after the three dots |
| !(3,5,...) | Any integer not part of this infinite sequence. The sequence doesn't extend to the left, only towards the right. So this rule would select the numbers 0, 1, 2, 4, 6, 8, 10, 12 and all remaining even numbers. |
| !(7,10,21,...,425) | Any integer not part of this finite sequence. |
| { * }[ (0 to 4) or (6,11,41) ] | It is possible to combine two or more rules using the boolean and/or operators. The example selects the first five items in every list of a tree and also the items 7, 12 and 42. |
Here are some examples of valid split masks.
| Split mask by branches | Description |
|---|---|
| { * } | Select all (the whole tree output as positive, and negative tree will be empty) |
| { *; 2 } | Select the third branch |
| { *; (0,1) } | Select the first two end branches |
| { *; (0, 2, …) } | Select all even branches |
| Split mask by branches and leaves | Description |
|---|---|
| { * }[(1,3,...)] | Select elements located at odd indices in all branches |
| { *; 0 }[(1,3,...)] | Select elements located at odd indices in the first branch |
| { *; (0, 2) }[(1,3,...)] | Select elements located at odd indices in the first and third branches |
| {*; (0,2,...) } [ (1,3,...) ] | Select elements located at odd indices in branches located at even indices |
| {*; (0,2,...) } [(0) or (1,3,...)] | Select elements located at odd indices, and index “0”, in branches located at even indices |
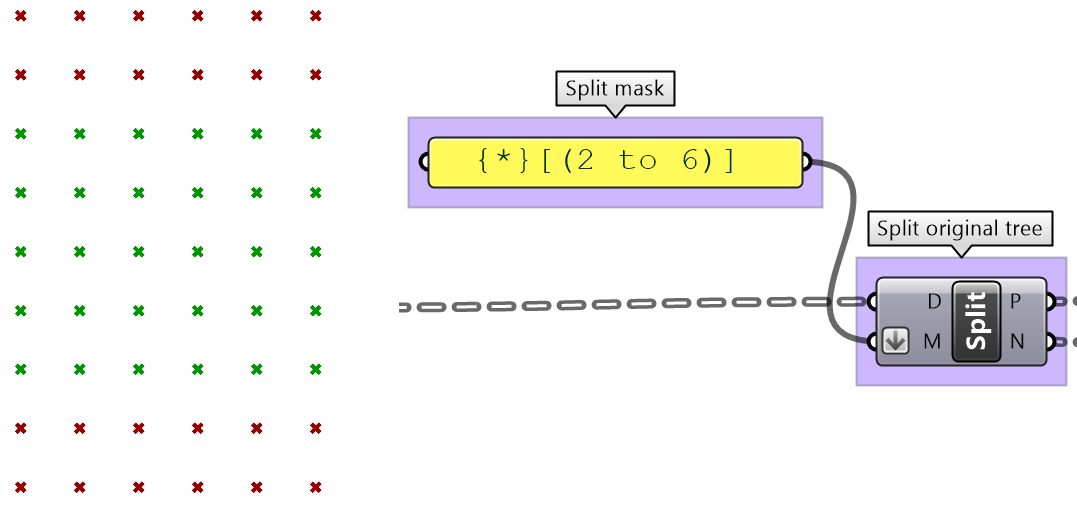
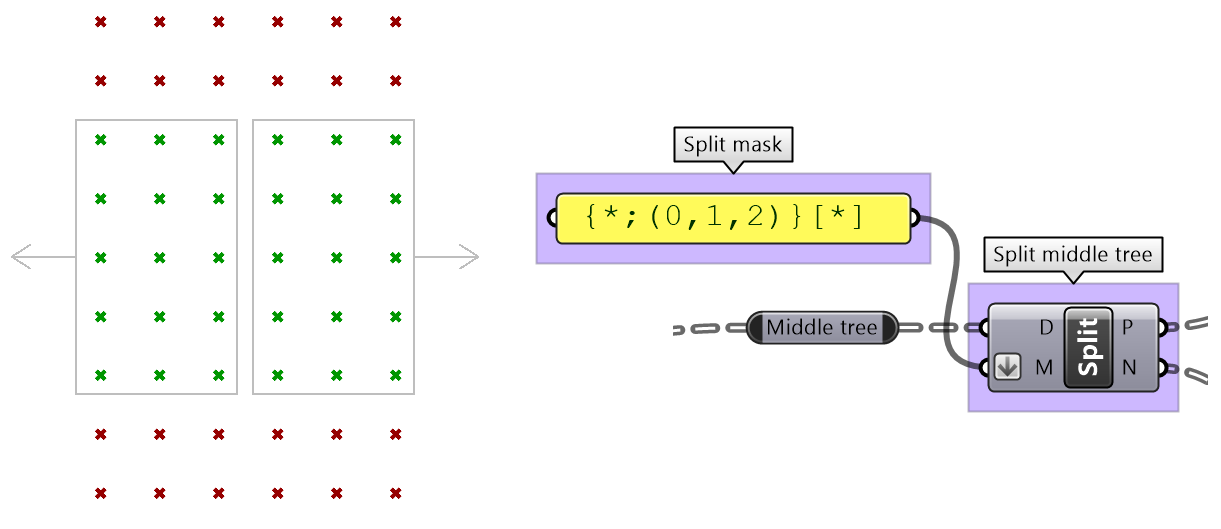
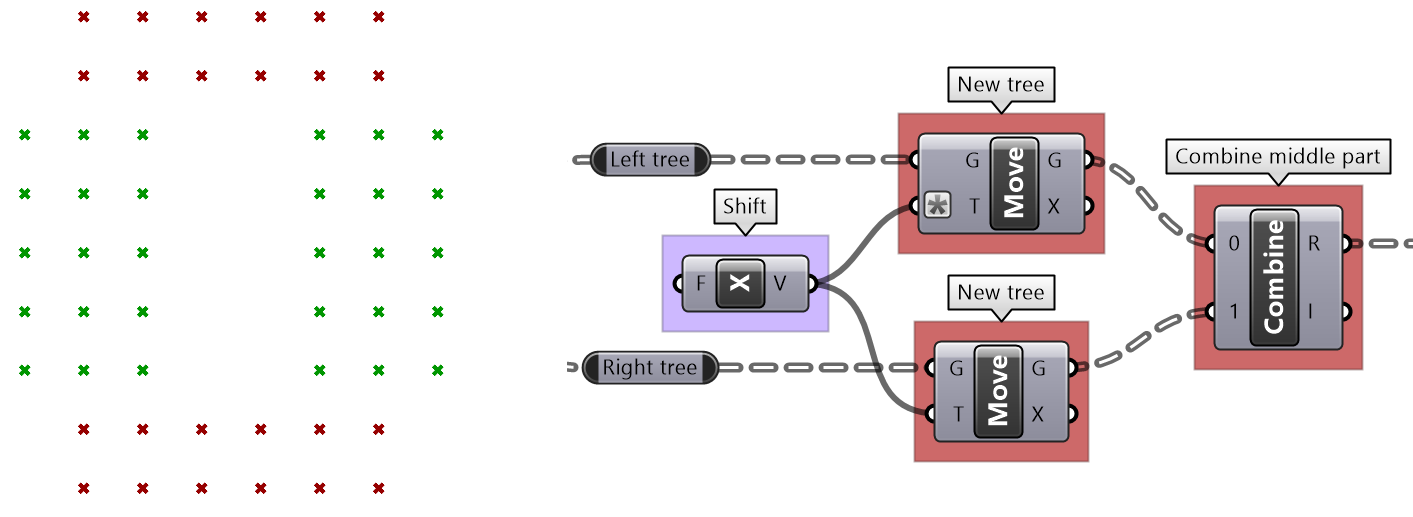
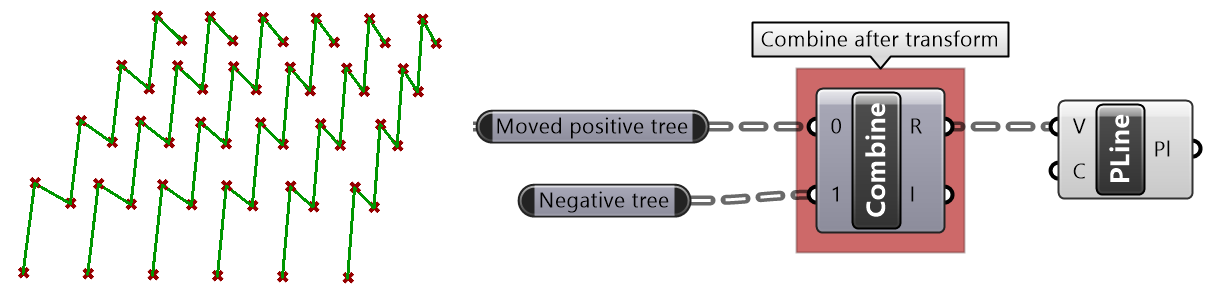
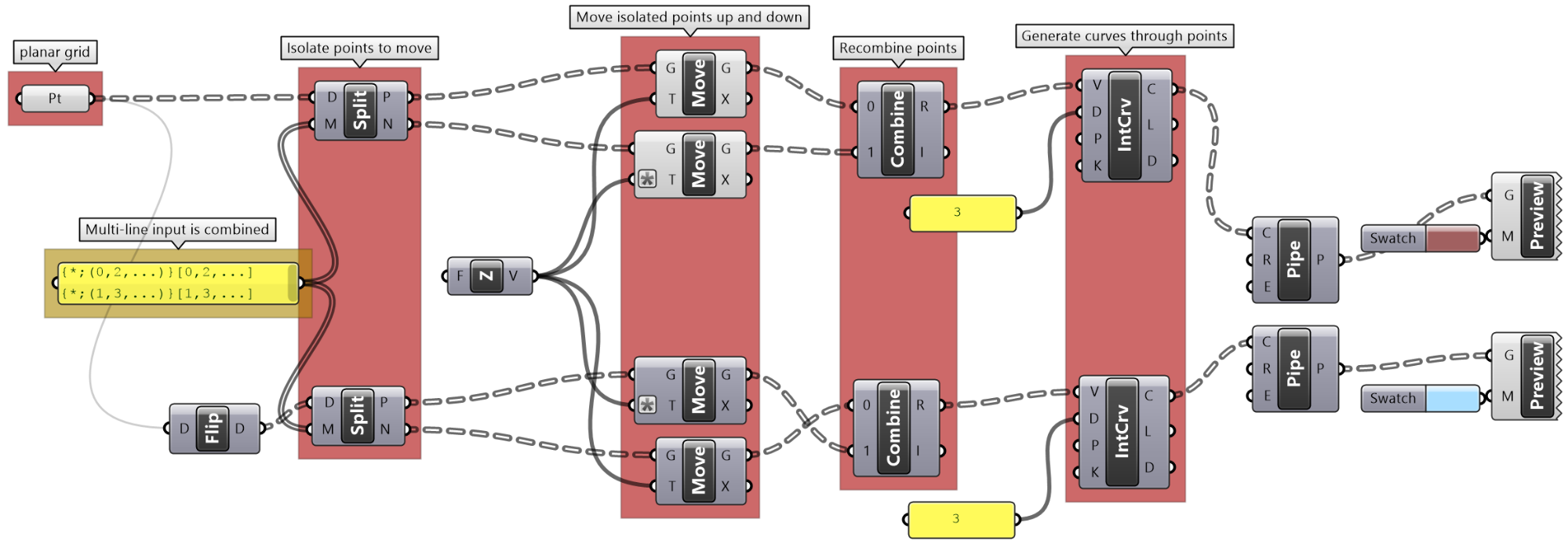
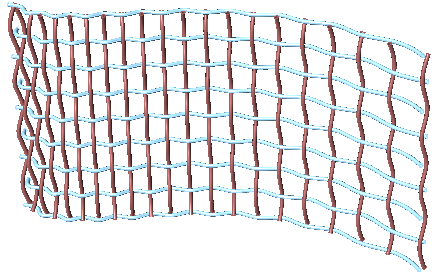
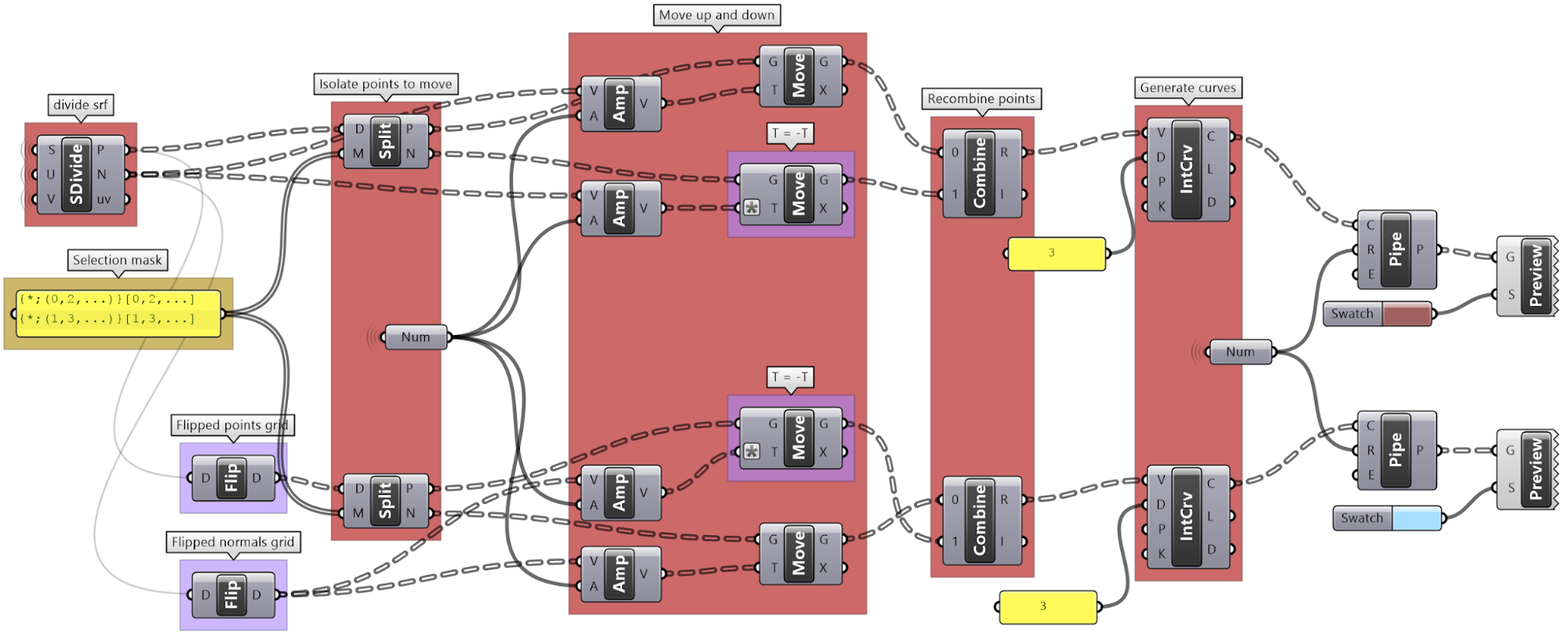
One of the common applications that uses split tree functionality is when you have a grid of points that you like to transform a subset of. When splitting, the structure of the original tree is preserved, and the elements that are split out are replaced with null. Therefore, when applying transformation to the split tree, it is easy to recombine back. Suppose you have a grid with 7 branches and 11 elements in each branch, and you’d like to shift elements between indices 1-3 and 7-9. You can use the split tree to help isolate the points you need to move using the mask: {*}[ (1,2,3) or (7,8,9) ], move the positive tree, then recombine back with the negative tree.
This is the GH definition that does the above using the Split Tree component.

One of the advantages of using Split Tree over relative trees is that the split mask is very versatile and it is easier to isolate the desired portion of the tree. Also the data structure is preserved across the negative and positive trees which makes it easy to recombine the elements of the tree after processing the parts.
| Tutorial 3.6.2.A: Split tree pattern | |||||
|---|---|---|---|---|---|
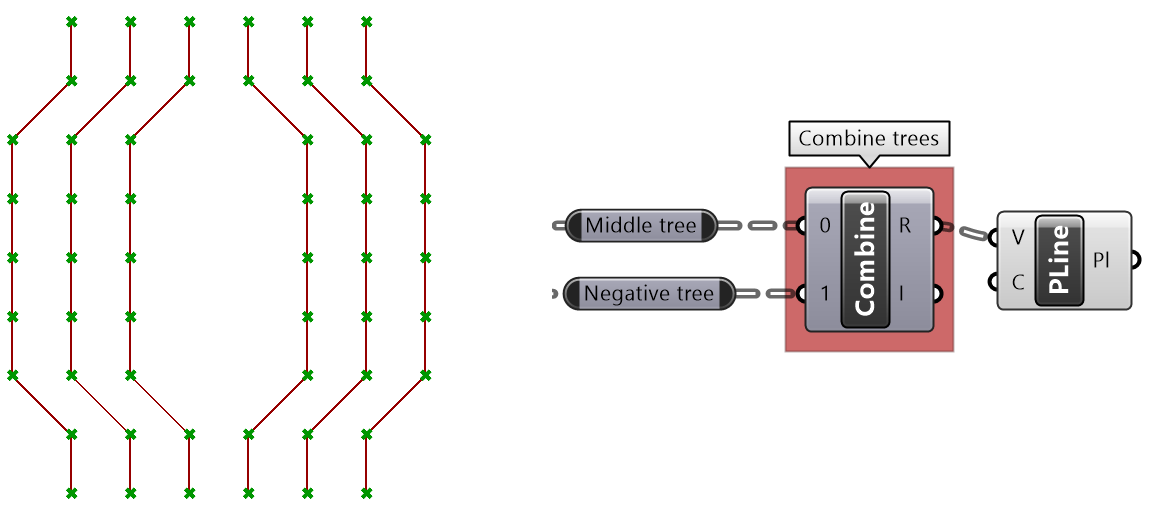
Given a 6x9 grid, use the split tree to generate the following pattern:
|
|||||
Solution...
|
| Tutorial 3.6.2.B: Split tree truss | ||||||
|---|---|---|---|---|---|---|
Given a grid, create the following truss system using the split tree method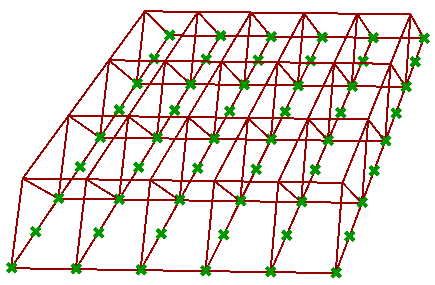
|
||||||
Solution...Solution video...
|
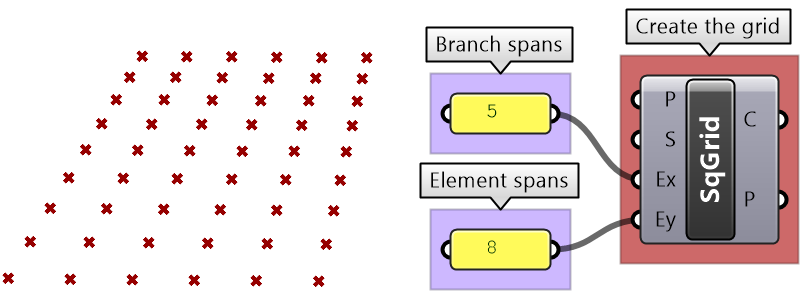
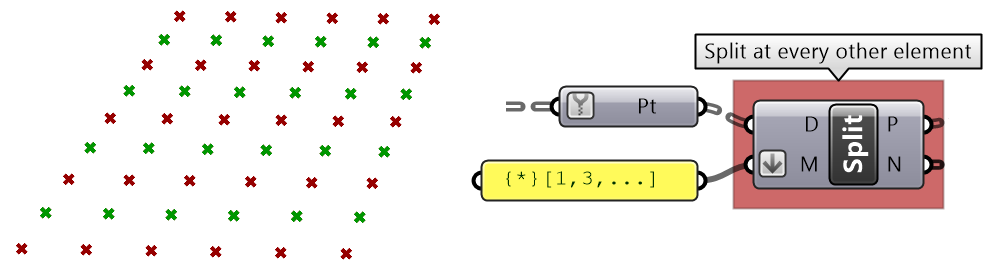
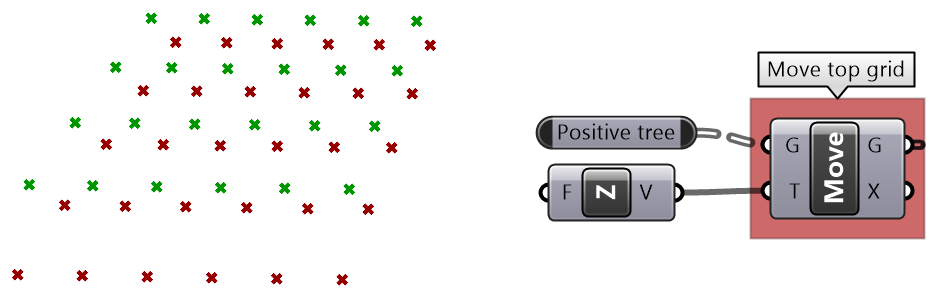
3.6.3 Path mapper
Why use the Path Mapper?
Syntax of the Path Mapper
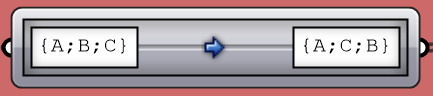
When dealing with complex data structures such as the Grasshopper data trees, you’ll find that you need to simplify or rearrange your elements within the tree. There are a few components offered in Grasshopper for that purpose such as Flatten, Graft or Flip. While very useful, these might not suffice when operating on multiple trees or needing custom rearrangement. There is one very powerful component in Grasshopper that helps with reorganizing elements in trees or change the tree structure called the Path Mapper. It is perhaps the least intuitive to use and can cause a loss of data, but it is also the only way to find a solution in some cases, and hence it pays to address here. The Path Mapper maps data between source and target paths. The source path is fixed, and is given by the input tree. You can only set the target path. There is a set of constants that you can use to help construct the mapping. Those are listed in the table below.
| Path Mapper Constants | Description |
|---|---|
| item_count | Number of items in the current branch |
| path_count | Number of paths (branches) in the tree |
| path_index | Index of the current path |
Let’s start by familiarizing ourselves with the syntax using built-in mappings inside the Path Mappers. If you right-muse-click on the mapper components, you can open the editor, and also access a bumber of default mapping functions that are commonely used.
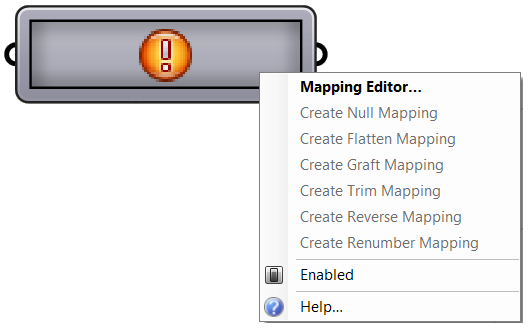
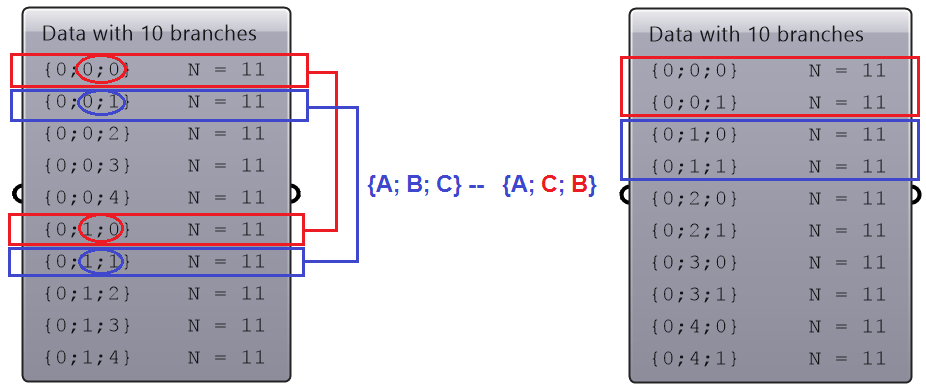
The Null Mapping does not change the data tree organization, but it offers a good start because it populates the editor with the input data structure. Set the mapping to Null Mapping and double click on the component to open the editor. The default tree source include the path only to start, but can add the data index part if needed for your mapping.
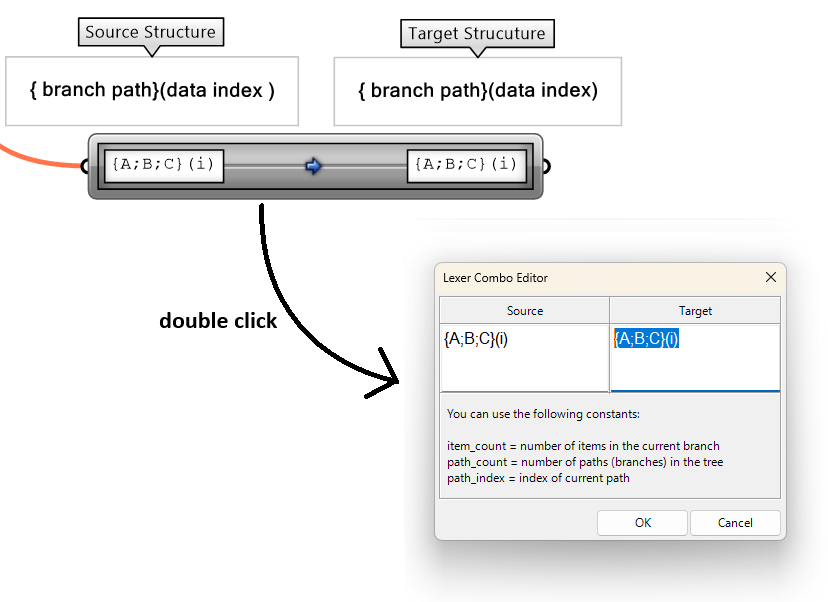
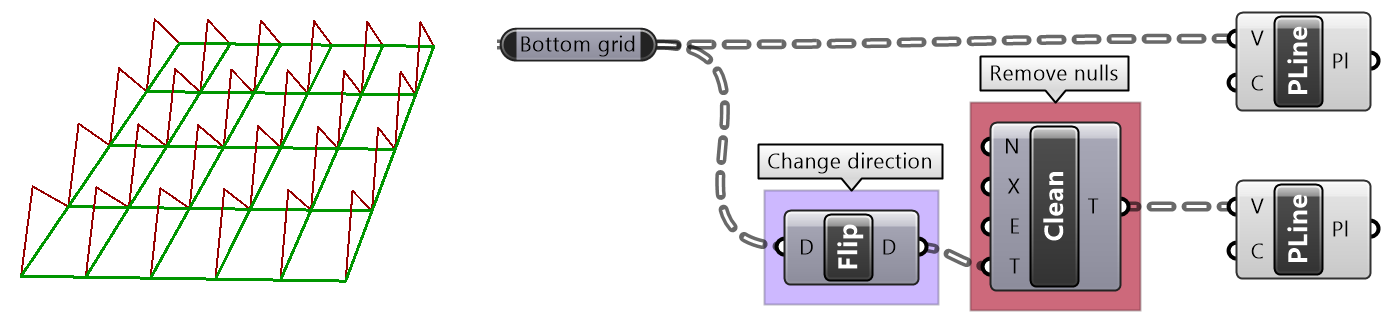
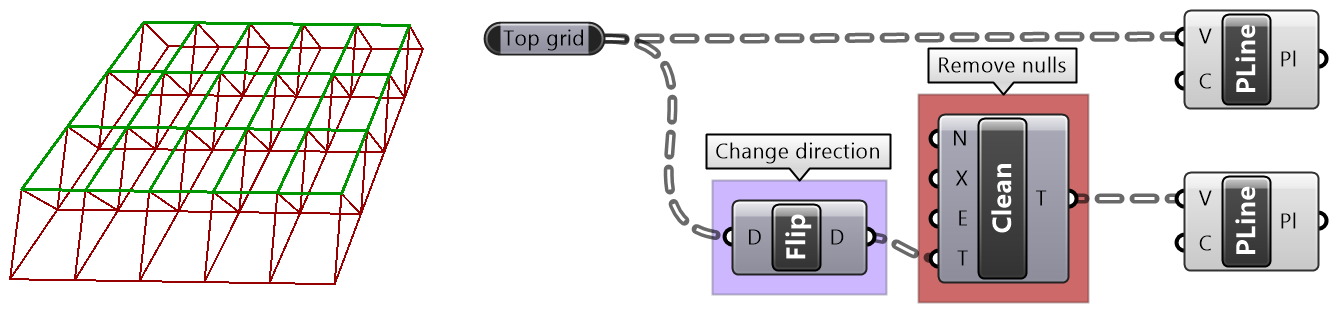
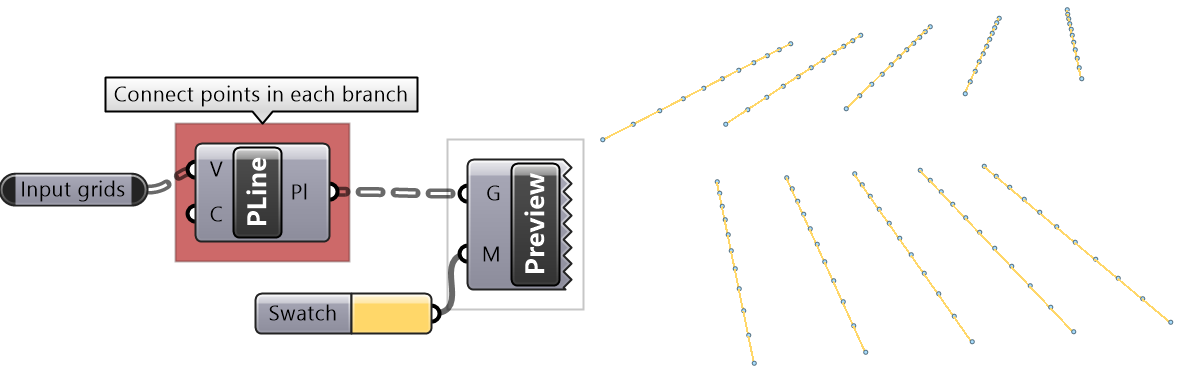
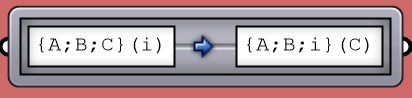
The following example examines different built-in mapping in the Path Mapper and how it changes the data structure. The Polyline component creates one polyline through each branch of the tree. Notice how different mapping affect the result.
| Mappings | ||
|---|---|---|
| Null | Output = Input tree | |
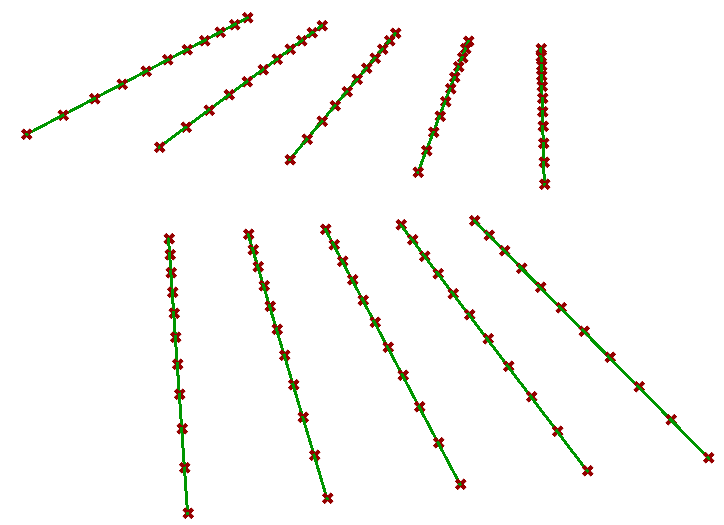 |
 |
|
| Flatten | Convert to a list | |
 |
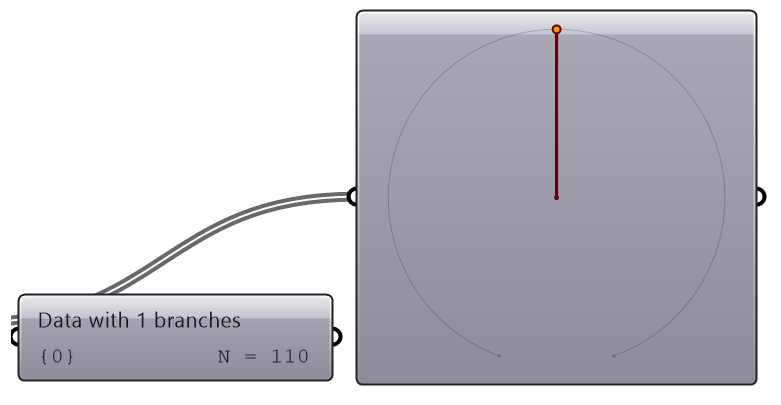 |
|
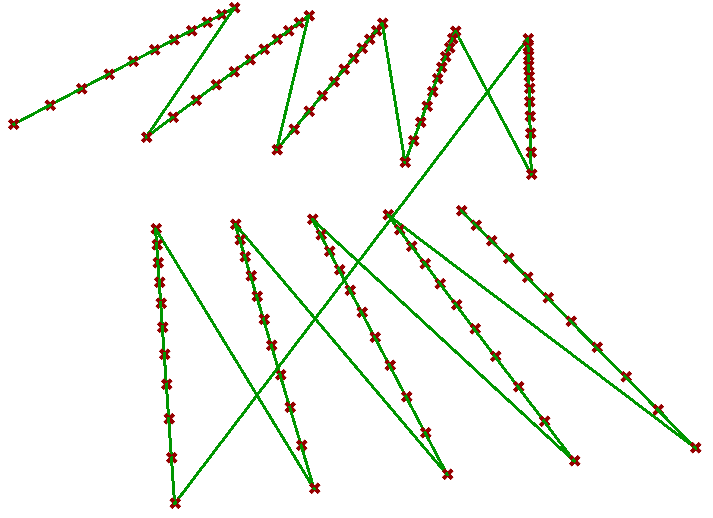
| Graft | Put leaves in branches | |
 |
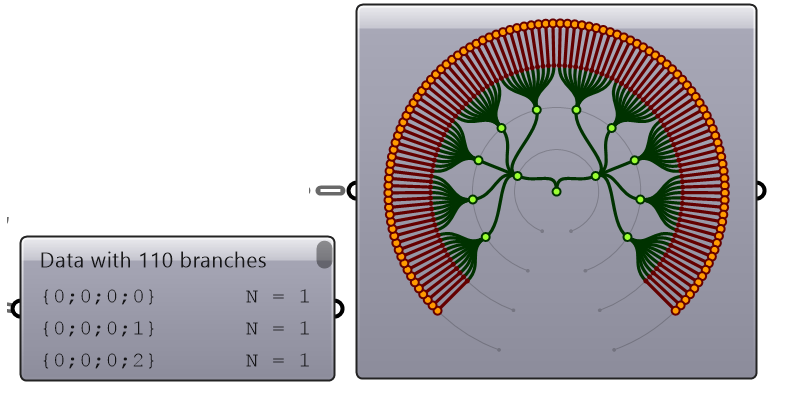 |
|
| Reverse | Reverse the tree | |
|
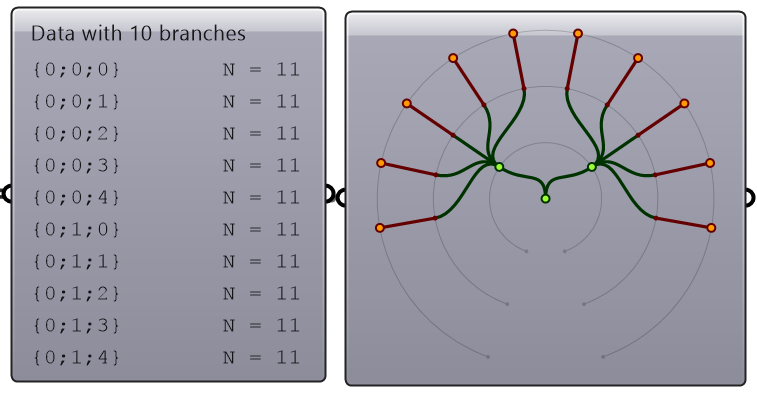 |
|
| Renumbering | Renumber branches | |
|
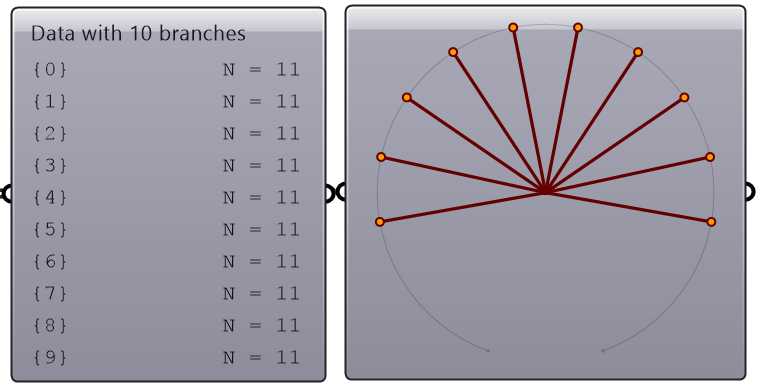 |
For more details about the Path Mapper, please refer to the help inside the component in Grasshopper.
| Tutorial 3.6.3.A: Partitions | ||||||
|---|---|---|---|---|---|---|
Given a grid, create the following truss system using the split tree method
|
||||||
Solution...
|

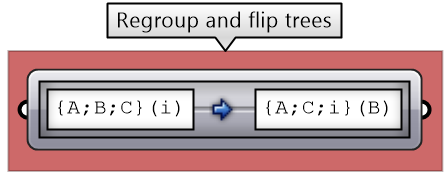
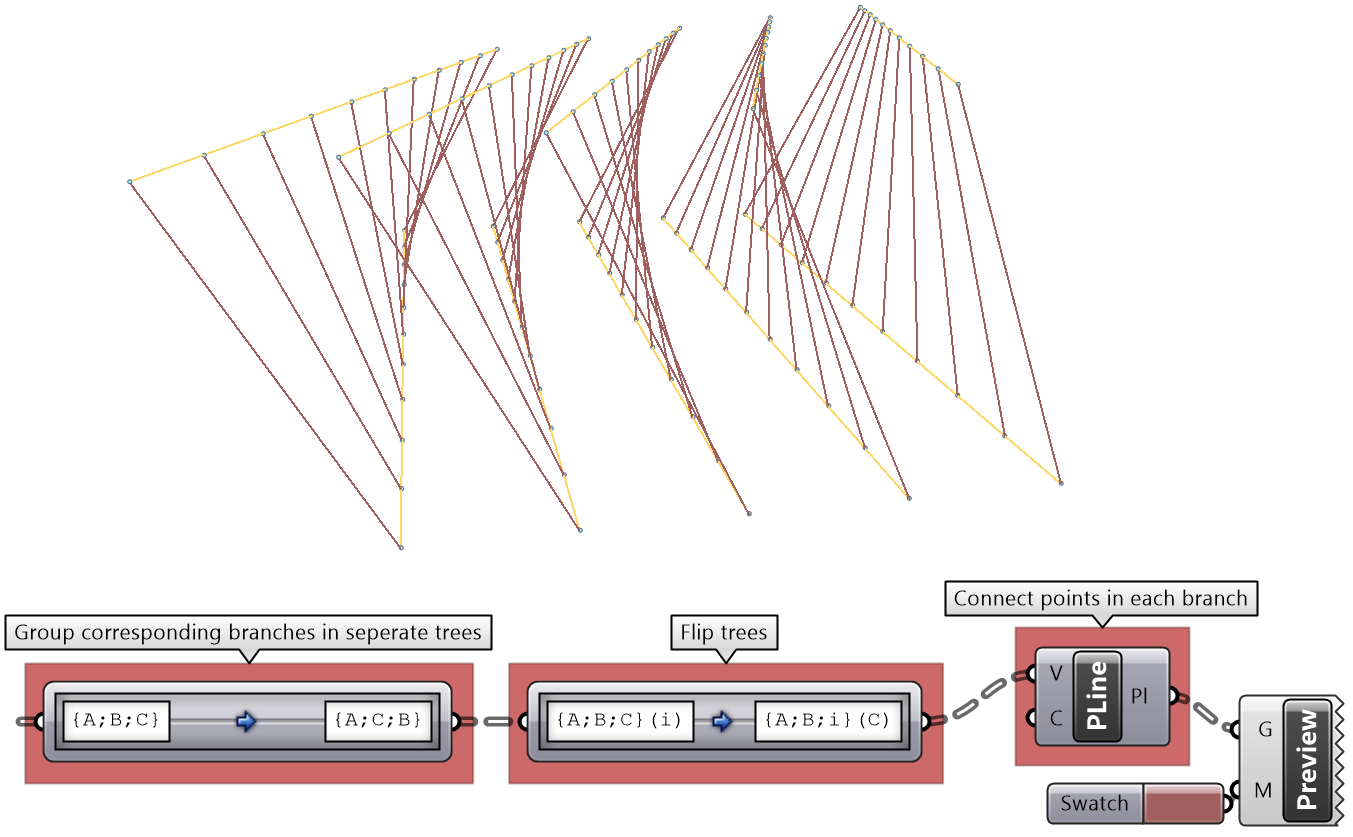
| Tutorial 3.6.3.B: Bruilding structure | |||||
|---|---|---|---|---|---|
Given the input tree of points, create the following structure.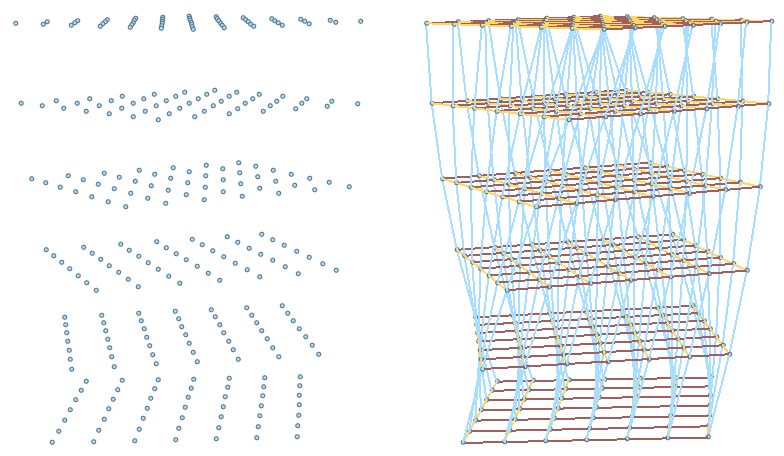
|
|||||
Solution...
|
3.7 Tutorials: advanced data structures
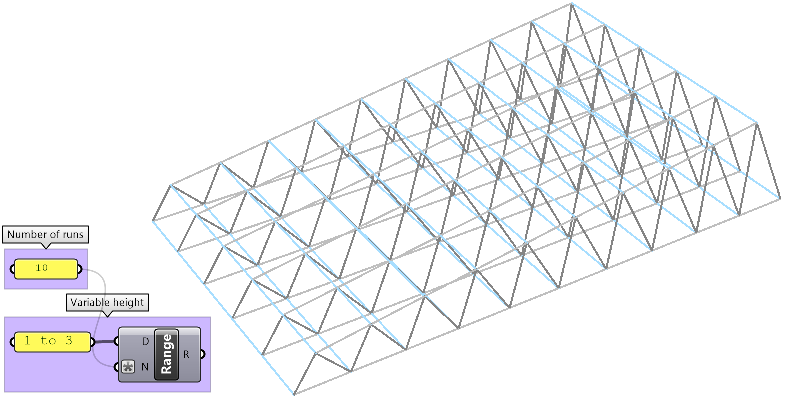
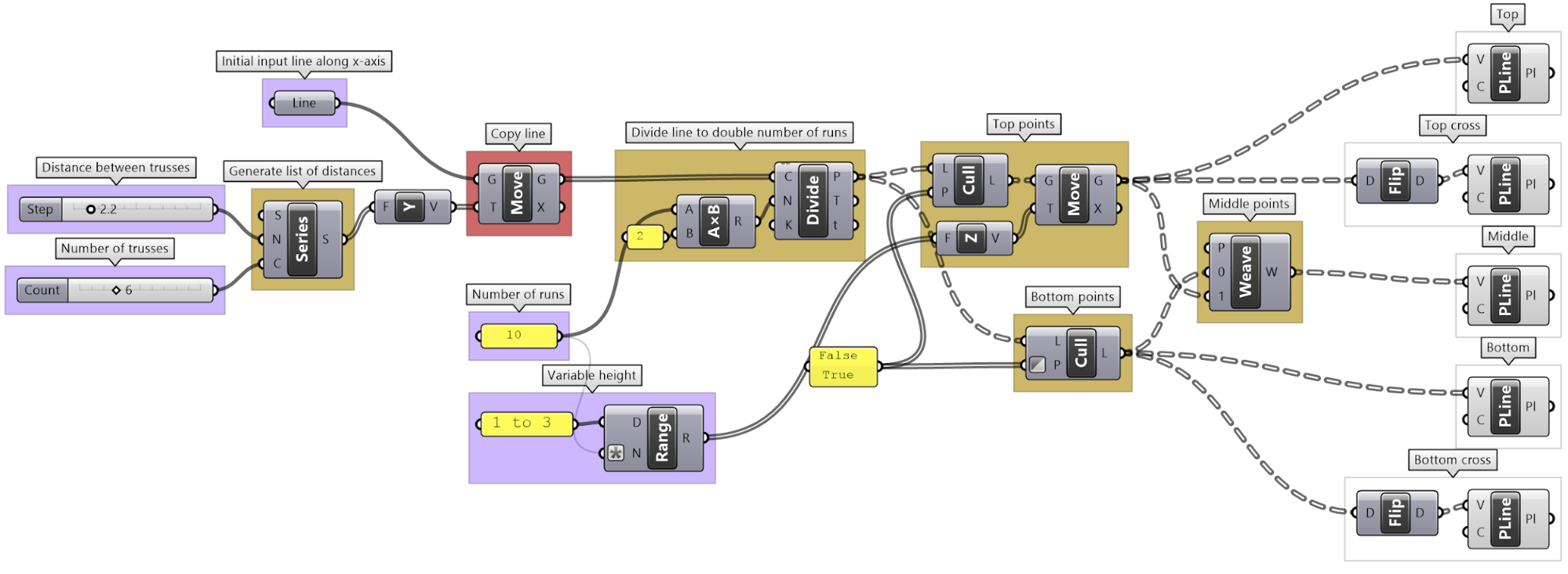
| Tutorial 3.7.1: Sloped roof | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Create a parametric truss system that changes gradually in height as shown in the image.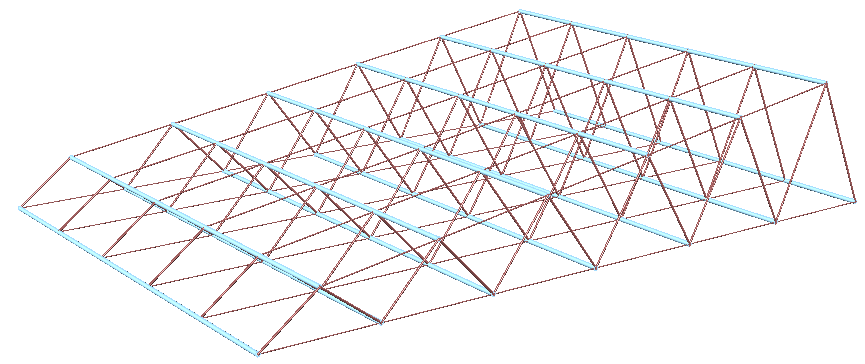
|
|||||||||||||||||
Solution...ownload GH file...
|


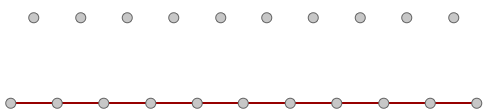
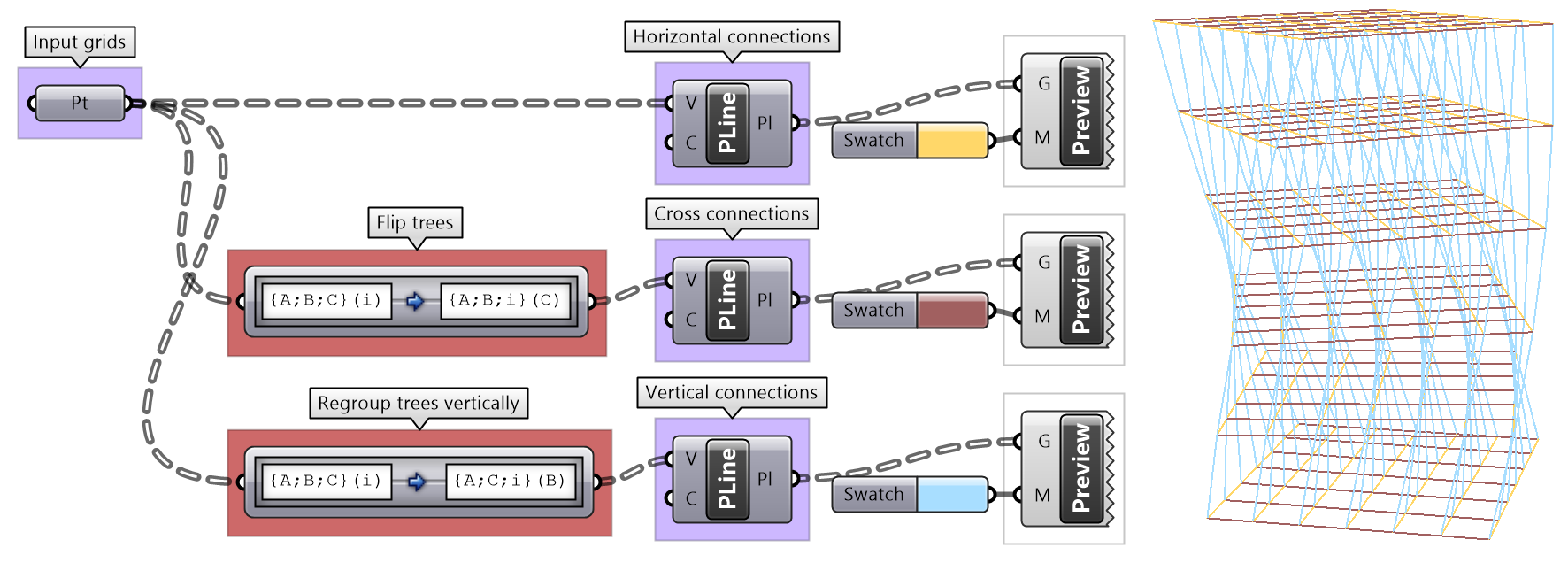
| Tutorial 3.7.2: Diagonal triangles | |||||
|---|---|---|---|---|---|
Given the input grid, use the RelativeItem component to create diagonal triangles
|
|||||
Solution...download GH file...
|
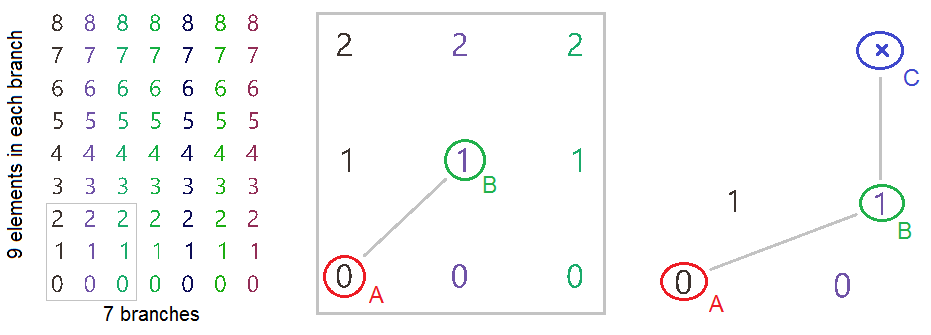
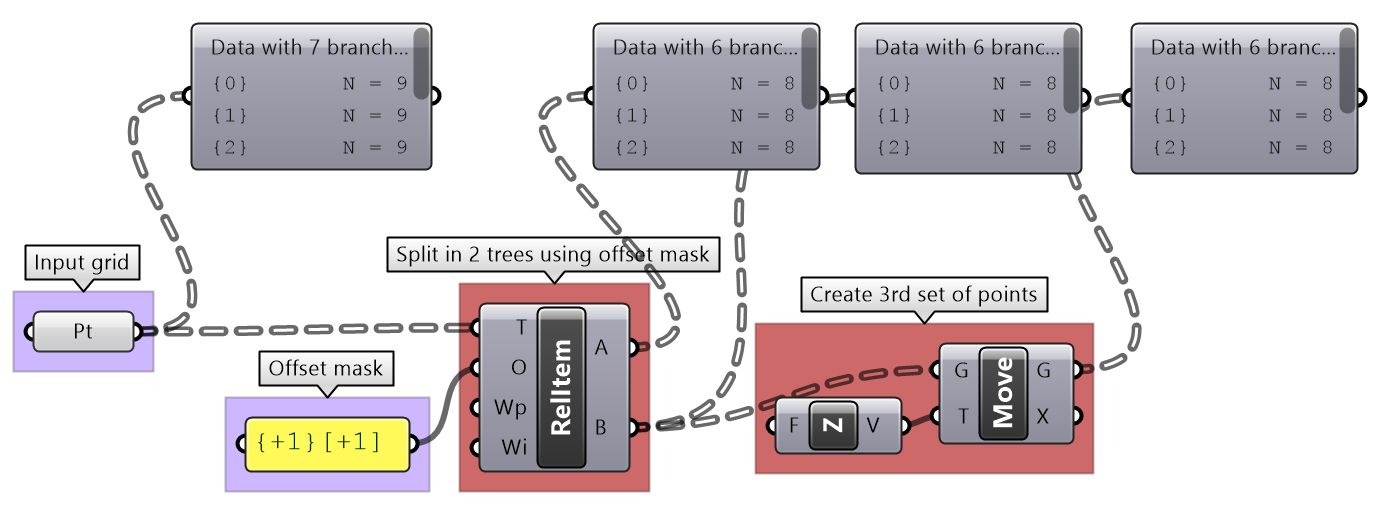
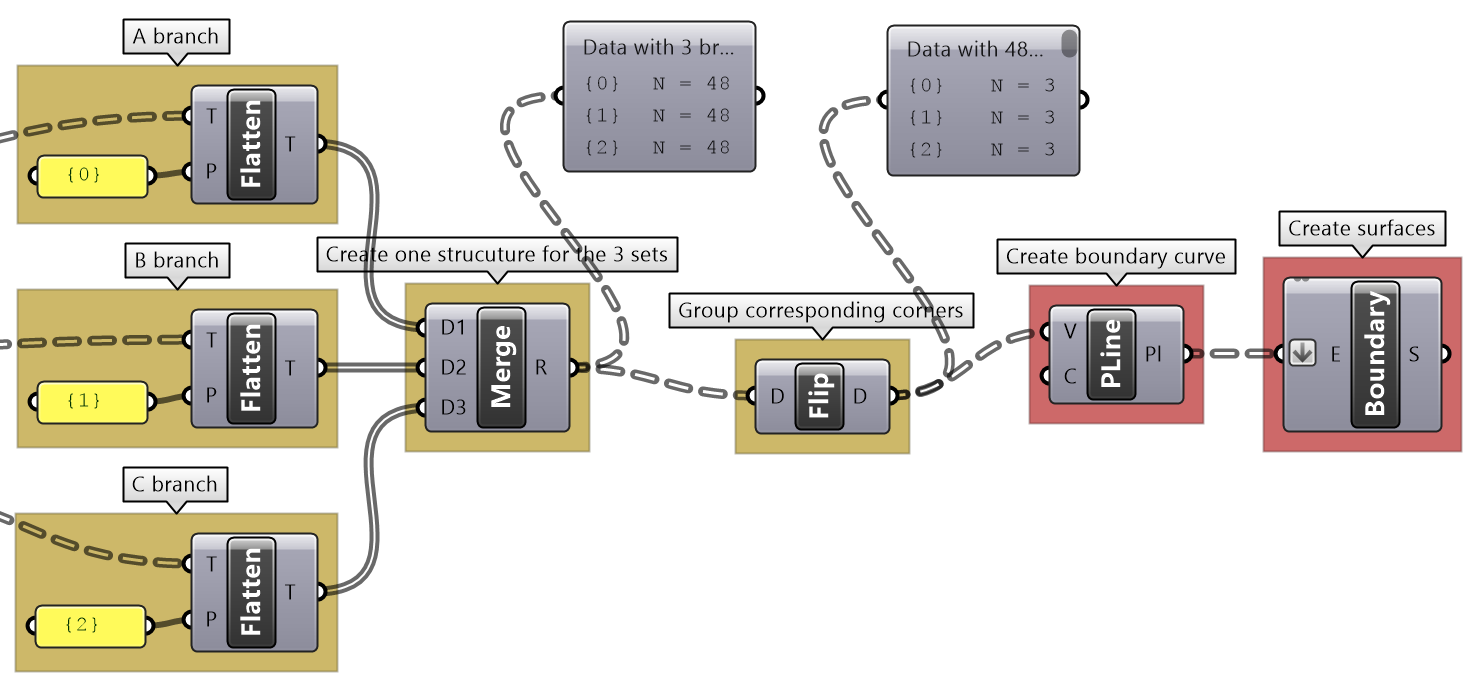
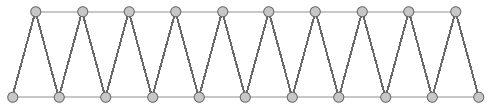
| Tutorial 3.7.3: Zigzag | |||||
|---|---|---|---|---|---|
Create the structure shown in the image using a base grid as input.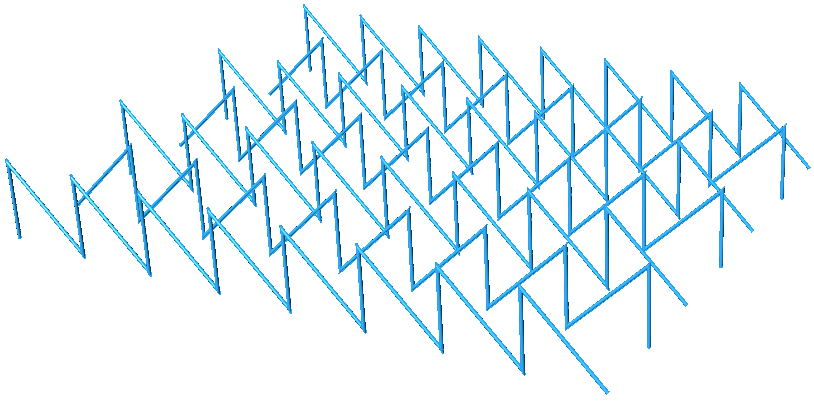
|
|||||
Solution...download GH file...
|
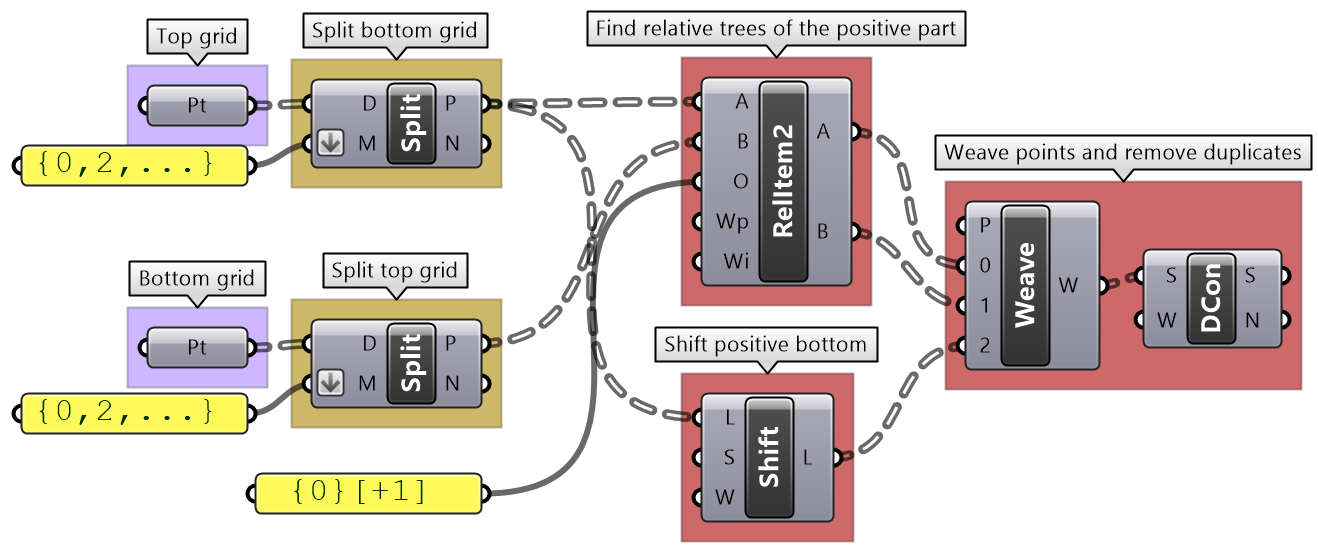
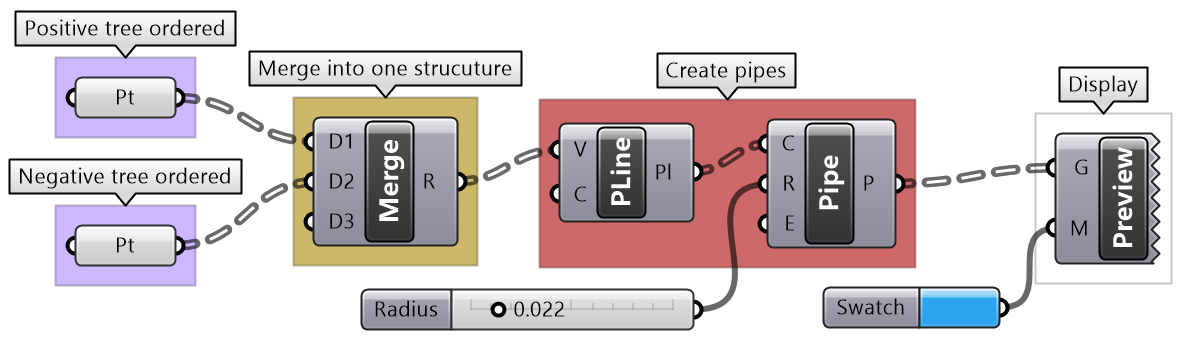
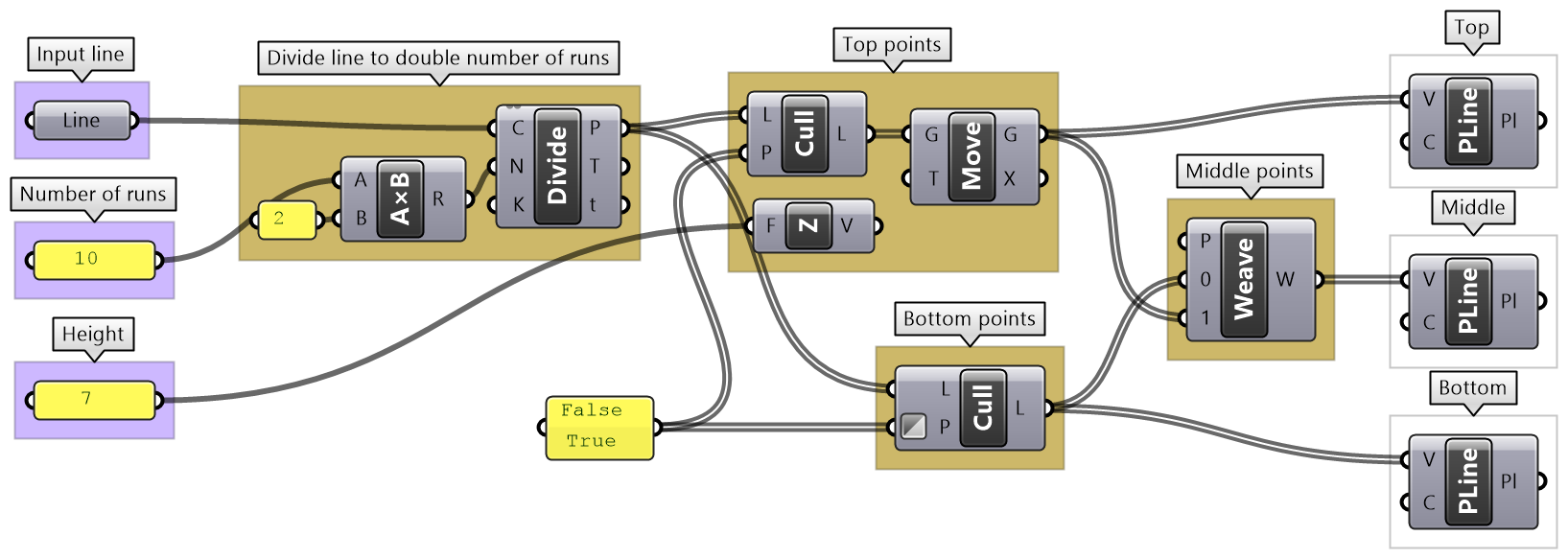
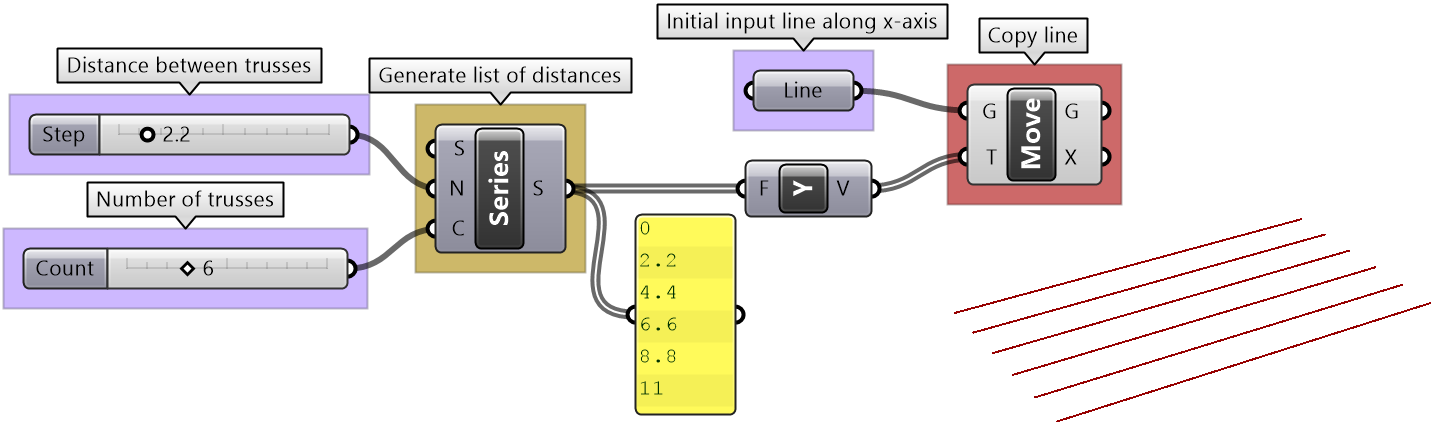
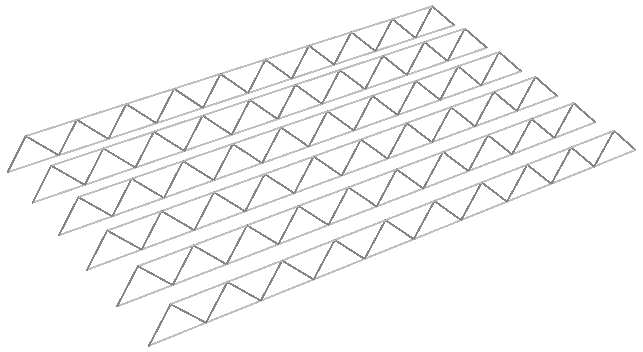
| Tutorial 3.7.4: Truss | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Create the structure shown in the image using a base grid as input.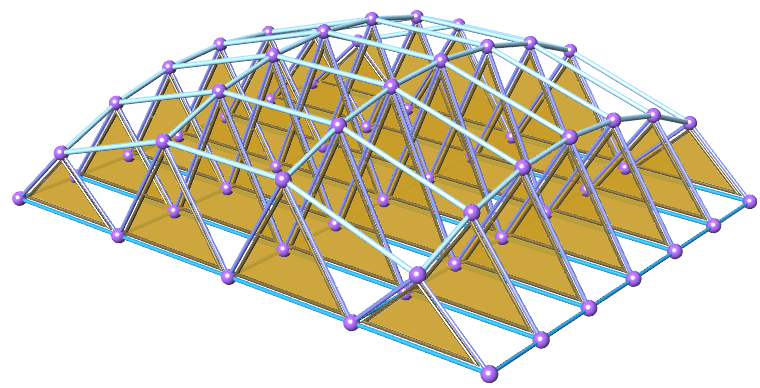
|
||||||||||||
Solution...download GH file...
|
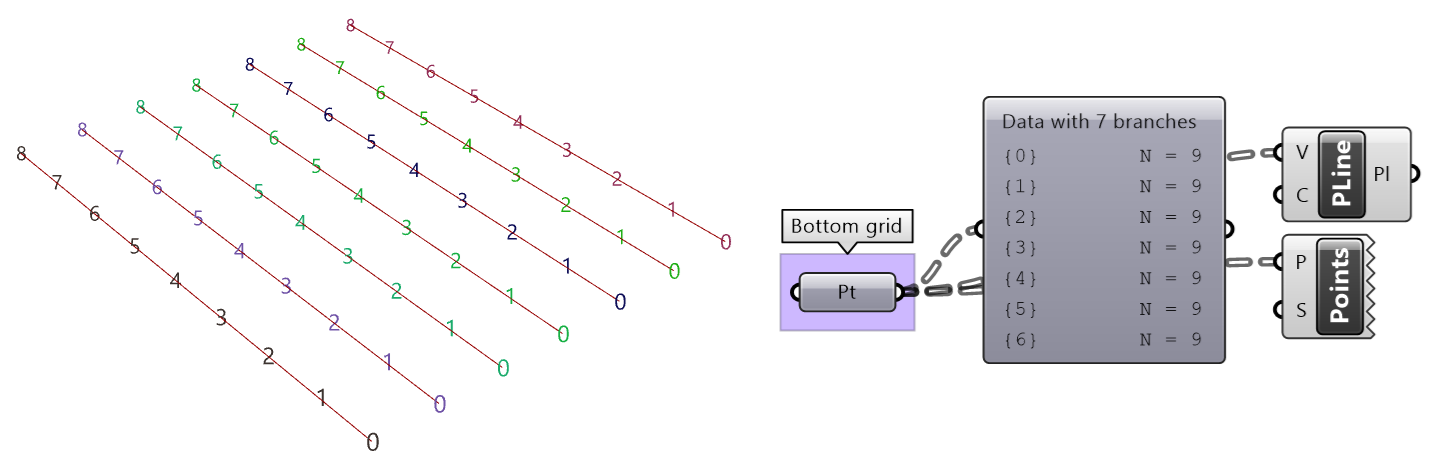
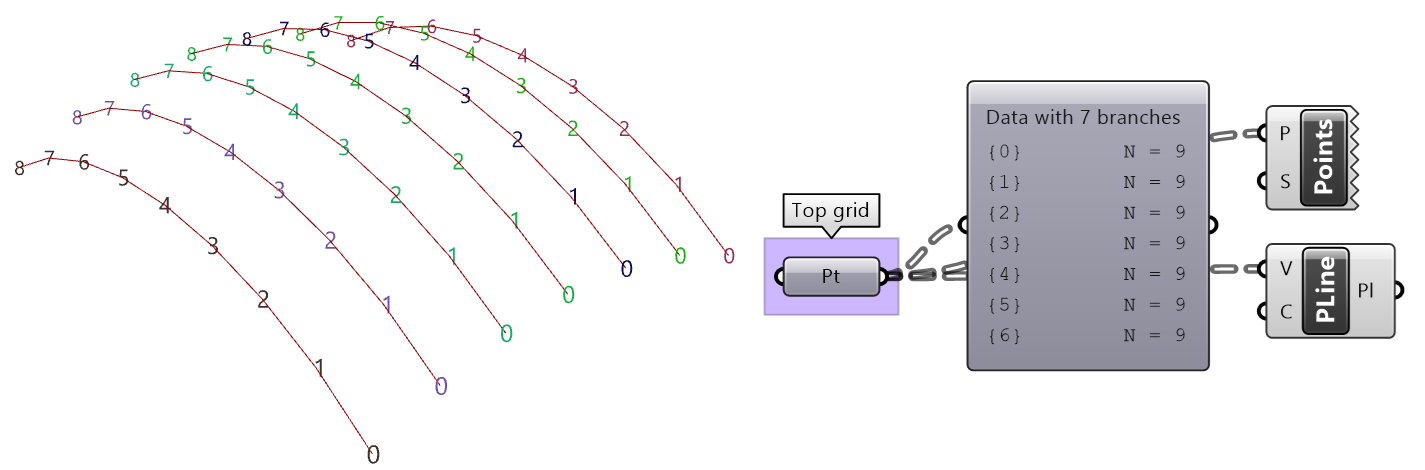
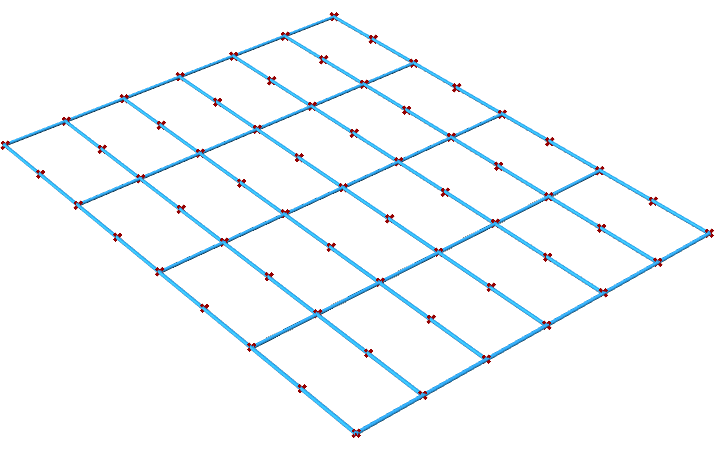
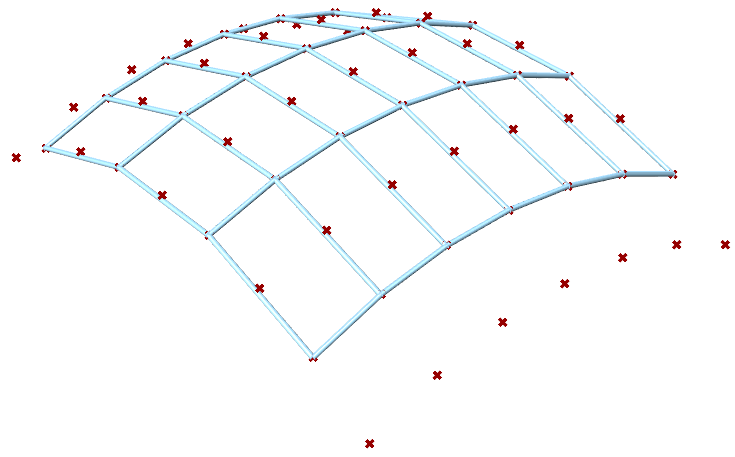

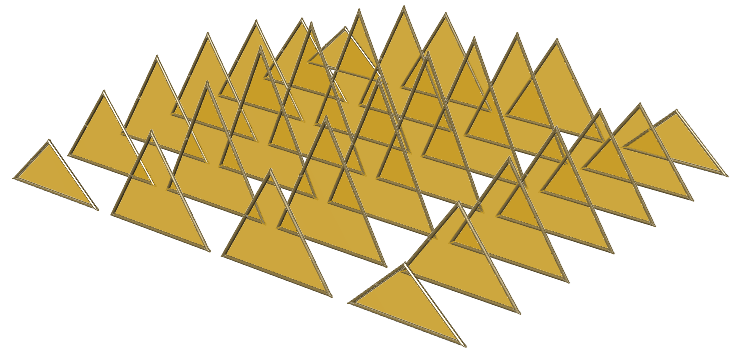
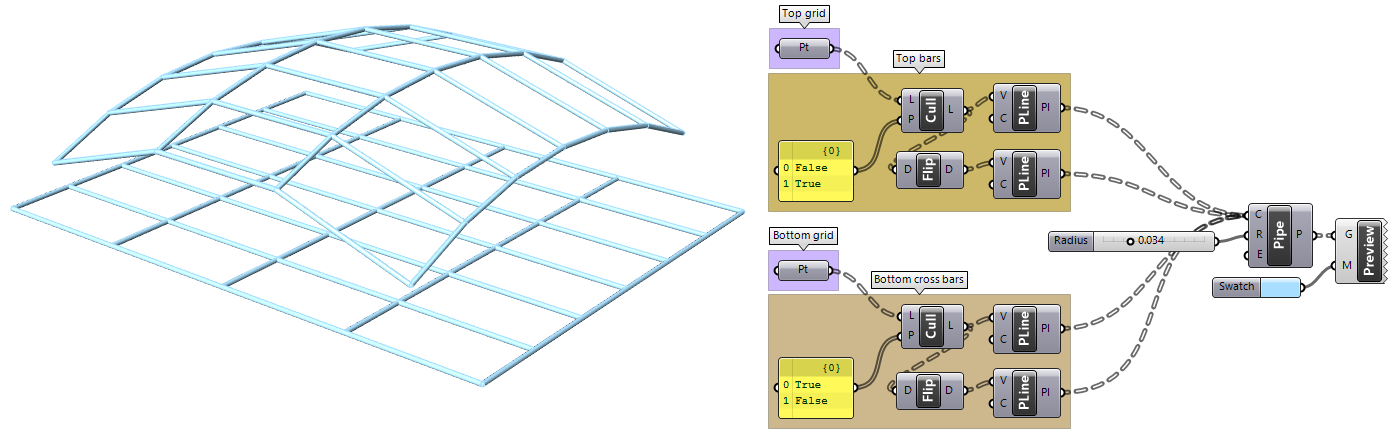
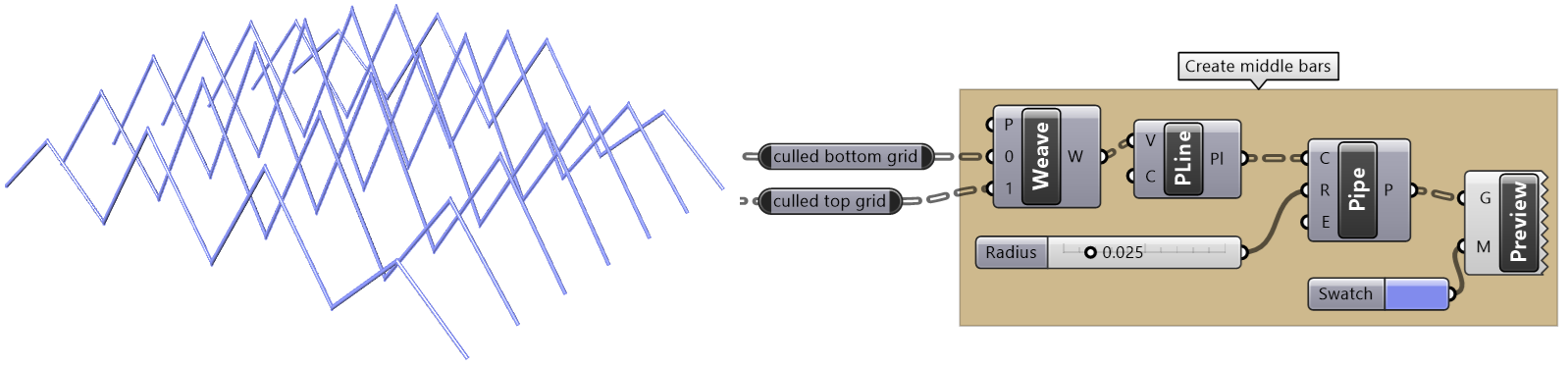
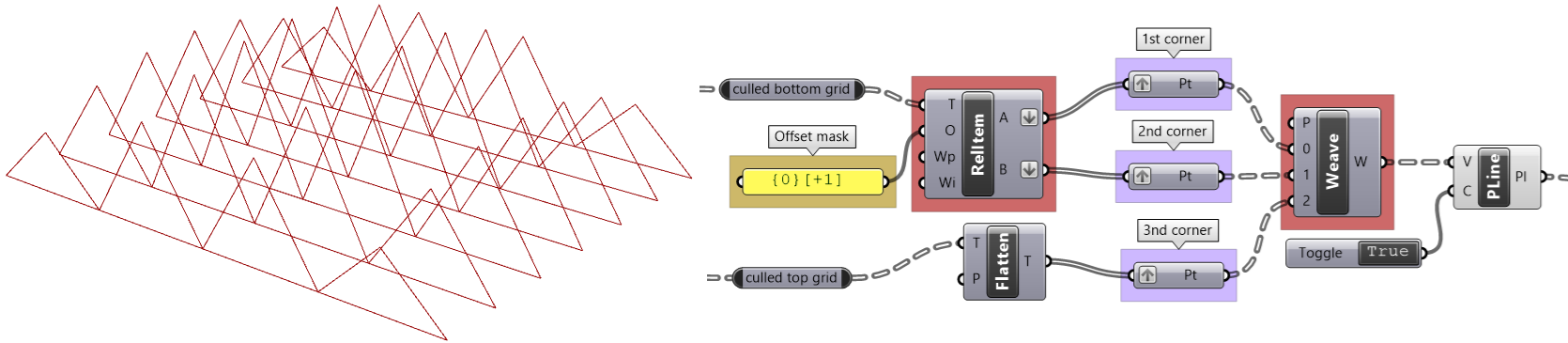

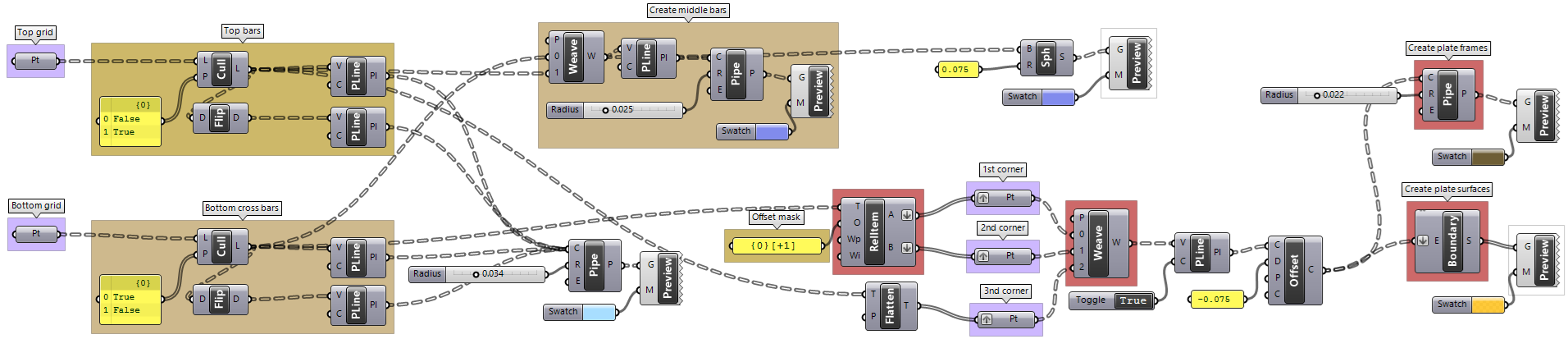
| Tutorial 3.7.5: Weaving | ||||||||
|---|---|---|---|---|---|---|---|---|
Create the structure shown in the image using a base grid as input.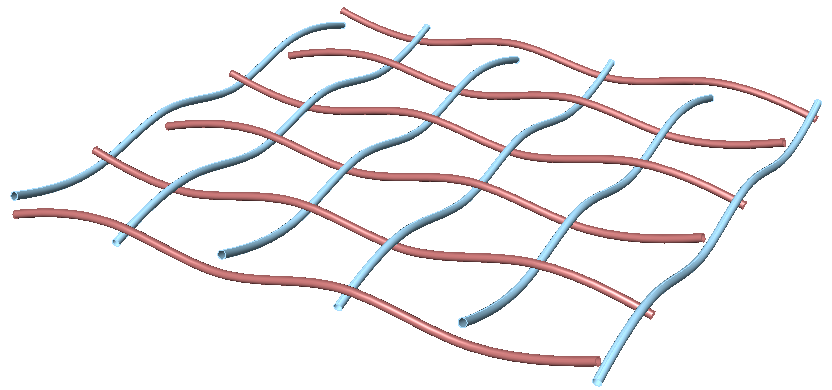
|
||||||||
Solution...download GH file...
|
End of guide
This is part 3-3 of the Essential Algorithms and Data Structures for Grasshopper.
